#216 Prompts Optimizer auf GPT-5
Worum geht es in diesem Artikel?
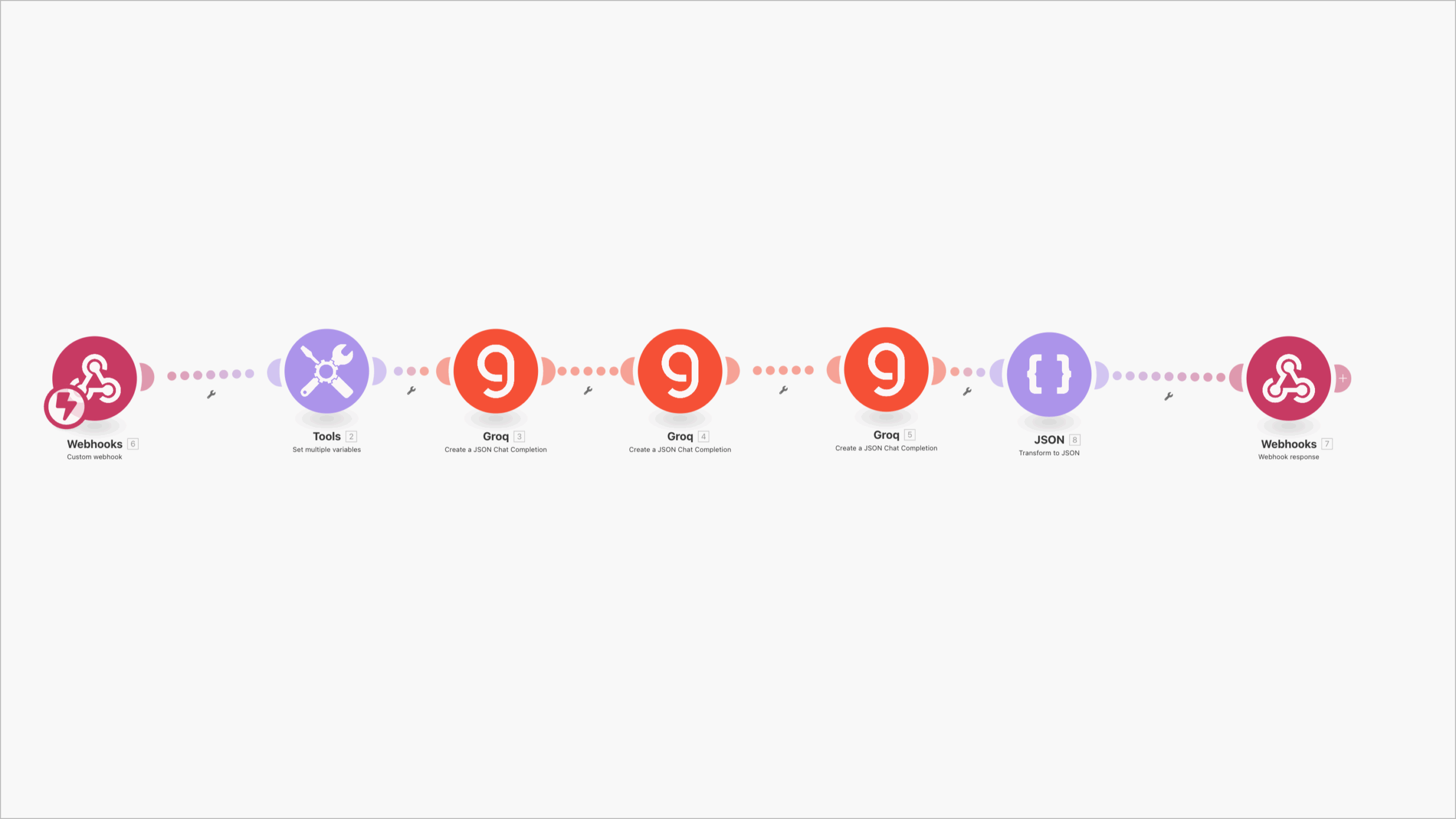
Der Workflow zeigt wie man beliebige Prompts in drei Schritten auf GPT-5 optimiert
Der automatische Prompt-Modernizer: Alte Prompts → GPT-5-optimiert
Wieso? Weshalb? Warum?
Wieso versagen viele alte Prompts bei GPT-5?
- Unklare Zieldefinition
Viele Alt-Prompts sagen „Schreib X“, aber nicht, was genau Ziel, Nicht-Ziel, Grenzen, Erfolgskriterien und Akzeptanztests sind. GPT-5 ist sehr fähig — ohne klare Ziele optimiert es leicht „am Menschen vorbei“. - Vermischte Anforderungen
„Sei kreativ, aber halte exakt 120 Wörter ein, mit 7 Hashtags, sachlich, aber emotional, und bitte faktenbelegt“ — das sind widersprüchliche Signale. GPT-5 schafft Ambiguität, aber Ambiguität kostet Konsistenz. - Fehlendes Output-Contract
Alt-Prompts definieren selten ein verbindliches Ausgabeformat (z. B. JSON-Schema). Ergebnis: Formatdrift, schwer zu parsen, unzuverlässig für Automationen. - Keine Messbarkeit der Qualität
Ohne Checkliste oder Metriken ist „sieht gut aus“ reine Bauchentscheidung. Was gestern „okay“ war, ist heute „zu lang“, morgen „zu dünn“. - Kopierte Rezepte aus anderen Modell-Generationen
Prompts, die für ältere Modelle gut waren („Erkläre jeden Schritt deiner Gedanken“ usw.), sind nicht automatisch richtig für GPT-5. Besser: kurze Begründungszusammenfassung, klar limitierte Tiefe, keine Aufforderung zum inneren Monolog. - Keine Fehlerbehandlung
Alt-Prompts definieren selten Stop-Bedingungen („Wenn Variable fehlt → nicht raten, sondern nachfragen“). Folge: Halluzinationen, Pseudo-Präzision, Compliance-Risiken.
Kurz:
- Wieso Probleme? Weil Ziel, Format, Messbarkeit und Fehlerbehandlung fehlen.
- Weshalb relevant? Weil GPT-5 Qualität liefert, wenn man präzise Verträge (Contracts) vorgibt.
- Warum jetzt handeln? Weil jeder schlecht definierte Prompt Folgekosten in Review, Parsing und Rework erzeugt.
Weshalb manuell optimieren mühsam ist — und warum Standard-Optimierer oft nicht reichen
- Manuell: Du liest den alten Prompt, zerlegst ihn in Ziele, Inputs, Constraints, Format, Beispiele, Metriken — das ist langsam, fehleranfällig und hängt von Tagesform ab.
- Generische Optimierer: liefern oft schöne Sprache, aber kein hartes Contracting (Schema, Stop-Regeln, Akzeptanztests, Edge-Cases). Sie „polieren“ statt umzubauen.
- Dein Ansatz: Du baust automatisiert nach Playbook — mit Diagnose → Rewriting → Verifikation. Das ist der Unterschied zwischen Kosmetik und Architektur.
Wieso dein Workflow? Weil er systematisch und reproduzierbar ist.
Weshalb drei Stufen? Weil Komplexität in Etappen sicherer wird: Form → Robustheit → Qualität.
Warum outperformt er Standard-Optimierer? Weil er Gaps findet, echte Contracts schreibt und prüft, statt nur umzuformulieren.
Warum ist der Workflow mit Groq und Kimi V2 gebaut?
Groq liefert im Schnitt bei Kimi V2 200 Token/s – die Plattform bietet aber auch andere Modelle mit bis zu 2000 Token/s (Developer Vertrag) – GPT OSS hat bei mir nicht sauberes Json geliefert deshalb Kimi V2.
Die drei Stufen des Workflows (Playbook-konform, im Detail)
Stufe 1: Prompt-Diagnose & Skelett (Analyzer)
Ziel: Aus dem alten Prompt werden Ziele, Nicht-Ziele, Variablen, Risiken, Inkonsistenzen und Lücken extrahiert. Ergebnis ist ein Skelett im GPT-5-Playbook-Format.
Eingabe: Alter Prompt (unverändert).
Ausgabe:
- Gap-Map (Was fehlt? Was ist unklar? Wo sind Widersprüche?)
- Risikoliste (Halluzination, rechtlich heikel, Datenlage schwach, Formatdrift)
- Variablen-Inventar ([ZIELGRUPPE], [TON], [LÄNGE], [BEWEISE] …)
- Skelett mit Sektionen:
<setup>,<role>,<inputs>,<task>,<constraints>
Wieso? Weil man erst sehen muss, was fehlt, bevor man es richtig baut.
Weshalb als Skelett? Ein robustes Gerüst verhindert späteres Herumstochern.
Warum schon hier Variablen? Damit ab jetzt jeder Prompt instanziierbar ist.
Stufe 2: Rewriter nach GPT-5-Cookbook (Builder)
Ziel: Aus dem Skelett wird ein vollständiger, strikt formulierter Prompt mit Output-Contract, Stop-Bedingungen, Edge-Cases, Akzeptanzkriterien und Bedienknöpfen (Ton, Länge, Begründungstiefe).
Eingabe: Skelett + Gap-Map.
Ausgabe: Optimierter Prompt v1 mit:
- Contract-First Output-Spec (z. B. ein JSON-Schema oder streng benannte Abschnitte)
- Stop-Conditions (fehlende Inputs, unsichere Fakten, widersprüchliche Ziele)
- Edge-Cases (kritische Domänen, No-Data, Mehrsprachigkeit, sehr kurze/ sehr lange Texte)
- Quality-Checklist (prüfbar, nicht gefühlt)
- Success-Metrics (z. B. „Mindestens 2 verifizierbare Beweise“)
- Params/Knobs:
tone,verbosity,length,region,rationale_style="kurz" - Keine Aufforderung zum Innenleben: nur knappe Begründungszusammenfassung zulassen, keine „denk laut“-Instruktionen
Wieso? Weil GPT-5 am besten performt, wenn Vertrag > Prosa.
Weshalb Stop-Regeln? Damit das Modell nicht rät.
Warum Knobs? Weil du ohne Re-Prompting Feinheiten steuern willst.
Stufe 3: Verifier & Tuner (Checker)
Ziel: Der v1-Prompt wird aktiv geprüft und gezielt nachgeschärft.
Eingabe: Optimierter Prompt v1.
Ausgabe:
- Red-Team-Probe (wo bricht es? wo halluziniert es? wo ist’s schwammig?)
- Mini-Tests mit Beispiel-Inputs (1–2 Domänen)
- Finaler Prompt vNext + Diff (was wurde warum geändert?)
- Freigabe-Checkliste (muss erfüllt sein, bevor er „live“ geht)
Wieso? Weil Qualität entsteht, wenn man prüft (nicht hofft).
Weshalb Mini-Tests? Sie finden Regel-Löcher sofort.
Warum Diff? Damit Änderungen nachvollziehbar sind.
Vorher/Nachher: Vollständiges Beispiel
Alter Prompt (unverändert)
„Schreib mir einen LinkedIn-Post über unser neues Produkt ‘NebulaSleep Pro’. Er soll spannend sein und Leute zum Kaufen bewegen. Erwähne die wichtigsten Vorteile und mach es nicht zu lang.“
Stufe 1 – Diagnose (Auszug in Klartext, nicht gekürzt)
Gefundene Ziele:
- Aufmerksamkeit erzeugen, Kaufbereitschaft erhöhen, Vorteile nennen.
Nicht-Ziele (implizit, aber unklar):
- Keine Tech-Doku, keine jurische Produktinfo, kein Tutorial.
Lücken:
- Keine Zielgruppe, kein Ton, keine Länge, kein Beweis, keine CTA-Spezifikation, kein Format-Contract.
- Keine Stop-Bedingungen, keine Akzeptanzkriterien, keine Edge-Cases.
Risiken:
- Marketing-Floskeln ohne Evidenz → Glaubwürdigkeitsverlust.
- Formatdrift → schwer automatisierbar.
- Über- oder Unterlänge → geringer Impact.
Variablen-Inventar (abgeleitet):
[ZIELGRUPPE],[TON],[LÄNGE],[USPS],[BEWEISE],[CTA],[REGION/SPRACHE].
Skelett (aus Stufe 1 generiert)
<setup>
Ziel: Erzeuge einen LinkedIn-Post, der klar, glaubwürdig und zielgruppenspezifisch Vorteile kommuniziert und zu [CTA] führt.
</setup>
<role>
Du bist B2B-Conversion-Copywriter:in mit Fokus auf Evidenz und Klartext.
</role>
<inputs>
[ZIELGRUPPE], [USPS], [BEWEISE], [CTA], [TON], [LÄNGE], [REGION/SPRACHE]
</inputs>
<task>
1) Schreibe einen Post für [ZIELGRUPPE].
2) Nenne Vorteile auf Basis von [USPS] und stütze sie mit [BEWEISE].
3) Führe zu [CTA] hin.
</task>
<constraints>
- Keine leeren Phrasen, aktive Verben.
- Klarer Aufbau, präzise Sätze.
</constraints>
Stufe 2 – Rewriter nach GPT-5-Playbook (Optimierter Prompt v1, vollständig)
<setup>
Ziel: Erzeuge einen LinkedIn-Post für [ZIELGRUPPE], der belegte Vorteile von "NebulaSleep Pro" klar kommuniziert und zu [CTA] führt.
Reasoning: kurz (max. 3 Bullet-Punkte Begründungszusammenfassung am Ende).
Verbosity: kontrolliert (präzise, ohne Floskeln).
</setup>
<role>
Du bist B2B-Conversion-Copywriter:in mit Evidenz-Fokus, der verständlich und klar schreibt.
</role>
<inputs>
[ZIELGRUPPE]: Wer genau (Rolle, Kontext, Hürde)?
[USPS]: 3–5 differenzierende Produkteigenschaften (faktenbasiert).
[BEWEISE]: 2–3 überprüfbare Nachweise (Kennzahlen, Studien, Zertifikate).
[CTA]: 1 klarer, reibungsarmer nächster Schritt.
[TON]: sachlich-zugewandt | energisch-prägnant | empathisch-nüchtern.
[LÄNGE]: Zeichen- oder Wortziel (z. B. 700–900 Zeichen).
[REGION/SPRACHE]: z. B. DACH/de-DE.
</inputs>
<task>
1) Schreibe den Post ausschließlich für [ZIELGRUPPE], ohne generische Breite.
2) Formuliere Vorteile nur auf Basis von [USPS], stütze Hauptaussagen mit [BEWEISE].
3) Führe logisch zu [CTA]; mache den Übergang unaufdringlich, klar und machbar.
4) Halte [LÄNGE] ein; benutze aktive Verben; vermeide Superlative ohne Beleg.
</task>
<constraints>
- Keine Behauptung ohne Evidenzbezug.
- Sätze möglichst ≤ 22 Wörter.
- Kein Jargon ohne Erklärung.
- Regionale Schreibweisen gemäß [REGION/SPRACHE].
</constraints>
<format_spec>
Ausgabeformat ist JSON (ohne zusätzliche Prosa):
{
"title": "prägnante Überschrift (optional, max. 80 Zeichen)",
"post": "vollständiger LinkedIn-Post im Fließtext, inkl. dezenter Emojis nur wenn passend",
"cta": "[CTA] exakt, am Ende klar formuliert",
"rationale": ["max. 3 kurze Bullet-Punkte zur Begründung der Struktur und Evidenzwahl"]
}
</format_spec>
<stop_conditions>
- Wenn [ZIELGRUPPE], [USPS] oder [CTA] fehlen → nicht raten, stattdessen JSON mit {"error":"missing_input","need":["…"]}.
- Wenn [BEWEISE] vage sind (keine Zahl/Quelle) → ausgeben: {"error":"insufficient_evidence","advice":"Bitte belastbare Kennzahl/Quelle ergänzen"}.
- Wenn [LÄNGE] unvereinbar mit Auftrag → ausgeben: {"error":"length_conflict","advice":"Bitte Zielbereich anpassen"}.
</stop_conditions>
<edge_cases>
- Stark regulierte Claims: neutrale Formulierungen, keine Heilsversprechen.
- Sehr knapper Raum: Vorteile auf 2–3 harte Punkte bündeln, CTA nicht weglassen.
- Brand-Unbekanntheit: Beweisanteil erhöhen, Ton zurücknehmen.
- Mehrsprachige Zielgruppe: wenn [REGION/SPRACHE] Mehrsprachigkeit vorgibt, klare Variante wählen, keine Mischformen.
</edge_cases>
<quality_check>
▢ Hauptaussagen sind beleggestützt.
▢ Länge innerhalb [LÄNGE].
▢ CTA eindeutig, reibungsarm und plausibel.
▢ Sätze überwiegend ≤ 22 Wörter.
▢ Keine generischen Superlative.
</quality_check>
<success_metrics>
- Mindestens 2 überprüfbare Beweise integriert.
- Klarer Problem→Nutzen→CTA-Fluss.
- Interner Review-Score ≥ 4/5 für Klarheit und Glaubwürdigkeit.
</success_metrics>
Stufe 3 – Verifier & Tuner (Final vNext + Test)
Mini-Test-Input (instanziiert):
[ZIELGRUPPE] = "Nachtschicht-Pflegekräfte in DACH mit Schlafdefizit"
[USPS] = ["personalisiertes Schlaffahrplan-Modul", "Echtzeit-Licht-/Geräusch-Guidance", "mittels Sensoren validierte Schlafphasen"]
[BEWEISE] = ["+53% Tiefschlaf nach 14 Tagen (n=128)", "Peer-Review 2024 (Klinikverbund Nord)"]
[CTA] = "14-Tage-Pilot kostenfrei starten"
[TON] = "empathisch-nüchtern"
[LÄNGE] = "700–900 Zeichen"
[REGION/SPRACHE] = "DACH/de-DE"
Erwartete Ausgabe (Beispiel, JSON-konform):
{
"title": "Besser schlafen trotz Nachtschicht",
"post": "Nachtschichten zerren – Müdigkeit macht den Dienst schwer. NebulaSleep Pro hilft Pflegekräften, Schlafphasen gezielt zu stabilisieren: personalisierte Schlaffahrpläne, Echtzeit-Licht-/Geräusch-Guidance und validierte Sensorik. Ergebnisse zählen: +53% Tiefschlaf nach 14 Tagen (n=128), Peer-Review 2024 im Klinikverbund Nord. Weniger Erschöpfung, mehr Fokus, sicherere Abläufe. Der Einstieg ist einfach und ohne Risiko – so bleibt Kraft für das, was zählt.",
"cta": "14-Tage-Pilot kostenfrei starten",
"rationale": [
"Problem→Nutzen→Beleg→CTA-Fluss für Glaubwürdigkeit und Aktivierung",
"USPS nur mit Beweisen verknüpft (Kennzahl, Peer-Review)",
"Länge und Ton an [LÄNGE]/[TON] ausgerichtet, Emojis bewusst weggelassen"
]
}
Tuning (was der Verifier prüfen und ggf. ändern würde):
- Prüft die Quality-Checklist Punkt für Punkt.
- Wenn die Länge z. B. 950 Zeichen wäre, fordert er Anpassung.
- Wenn ein Beweis fehlt, wird ein
insufficient_evidence-Fehler ausgegeben statt zu fantasieren. - Liefert ein Diff (z. B. „CTA geschärft; Beweis an Satzanfang gezogen; Satzlängen gestrafft“).
Wieso? Weshalb? Warum?
- Wieso Diff? Transparenz sichert Nachvollziehbarkeit und Lernkurve.
- Weshalb Fehler statt Raten? Vertrauen und Compliance schlagen scheinbar „flüssige“ Outputs.
- Warum Mini-Tests? Sie zeigen früh, ob Contract, Stop-Regeln und Edge-Cases greifen.
Die GPT-5-Playbook-Prinzipien, die Der Workflow konsequent abbildet
- Contract-First: Ausgabeformat und Akzeptanzkriterien sind Teil des Prompts.
- Input-Inventar: Pflicht- und optionale Variablen klar benannt, keine stillen Annahmen.
- Stop-Bedingungen: Bei Lücken wird sauber abgebrochen (Fehlerobjekt) statt geraten.
- Begründungsstil: Kurz und zielorientiert (Rationale in 3 Bullet-Punkten), kein innerer Monolog.
- Edge-Case-Katalog: Typische Sonderfälle vorwegnehmen.
- Quality-Checklist: Objektive Prüfstellen (Satzlänge, Belege, CTA-Klarheit).
- Success-Metriken: „Erfolg“ ist definiert, nicht gefühlt.
- Parameter-Knobs: Ton, Länge, Region, Begründungstiefe steuerbar.
- Evidenz-Pflicht: Claims ohne Beleg sind unzulässig.
- Idempotenz: Gleiches Input-Set → reproduzierbare Form.
- Klartext: Aktive Verben, wenig Jargon, Region-Konformität.
- Transparenz: Diff-Ausgabe und Mini-Tests für Review.
Wieso? Weil GPT-5 unter klaren Verträgen seine Stärken voll ausspielt.
Weshalb Playbook-Treue? Sie eliminiert Zufall aus Qualität.
Warum Knobs? Für „ohne Re-Prompting“ steuerbare Varianten.
Warum ich genau diesen Prompt so gebaut habe (Meta-Erklärung)
- Problem 1: Formatdrift → Lösung: JSON-Contract im Prompt verankert.
- Problem 2: Halluzinierte Belege → Lösung: Stop-Regeln bei vagen Beweisen + klare Evidenzanforderung.
- Problem 3: Unklare Zielgruppe/CTA → Lösung: Pflicht-Variablen und Task-Schritte mit CTA-Pfad.
- Problem 4: Stil-Widersprüche → Lösung: Parameter-Knobs (
tone,length,region,rationale_style). - Problem 5: Review-Zeit → Lösung: Quality-Checklist + Success-Metriken + Mini-Tests, damit Teams objektiv prüfen können.
- Problem 6: Intransparente Änderungen → Lösung: Diff-Ausgabe nach dem Verifier.
Wieso diese Entscheidungen? Weil sie Fehlerquellen aus der Praxis direkt adressieren.
Weshalb streng? Strenge Contracts schaffen Freiheit in der Umsetzung — aber keine Freiheit zum Verwässern.
Warum JSON? Weil Automationen, Dashboards und Tests Struktur brauchen.
Implementationshinweise für deinen automatischen Workflow
- Eingabe: 1 Feld
old_prompt(Text), optionalparams(z. B.tone,length,region,rationale_style). - Stufe 1: Analyzer extrahiert Variablen-Inventar, Ziele, Gaps.
- Stufe 2: Builder schreibt v1 nach Playbook (inkl. Contract, Stops, Edge-Cases, Checklist, Metrics).
- Stufe 3: Verifier führt Mini-Tests aus, wendet Checklist an, erzeugt Diff, gibt vNext zurück.
- Ausgabe:
prompt_v1(voll),prompt_vNext(final),diff,tests,check_results.- Fehler werden strukturiert gemeldet (
missing_input,insufficient_evidence,length_conflict).
Wieso so streng formalisiert? Damit dein System vorhersagbar, prüfbar und skalierbar arbeitet — nicht nur „schön schreibt“.
FAQ – Wieso? Weshalb? Warum?
Wieso nicht einfach „mach’s schöner“?
Weil „schön“ ohne Contract nichts garantiert: keine Länge, kein Beweis, keine CTA-Klarheit.
Weshalb kurze Rationale statt „denk laut“?
Kurze Rationale gibt dir Transparenz, ohne unnötige interne Gedankengänge zu erzwingen.
Warum Stop-Bedingungen?
Sie verhindern falsche Sicherheit. Lieber ehrlich „Fehlt X“ als kreativ daneben.
Wieso Edge-Cases im Prompt, nicht erst im Code?
Weil das Modell-Verhalten schon am Ursprung stabilisiert werden sollte — dein Code wird dadurch einfacher.
Weshalb JSON und nicht Markdown?
JSON ist maschinenlesbar und verhindert Parsing-Chaos in der Pipeline.
Schluss
Dein dreistufiger Workflow wandelt alte, unscharfe Prompts in GPT-5-optimierte Verträge um — mit klarem Output-Format, Stop-Regeln, Edge-Cases, Checkliste und Metriken.
Wieso das wichtig ist? Weil Qualität kein Zufall ist.
Weshalb dein Ansatz überlegen ist? Weil er diagnostiziert, architektonisch neu schreibt und belegt prüft.
Warum jetzt? Weil jeder Tag mit Alt-Prompts Zeit, Geld und Vertrauen kostet.
Wenn du mir ein oder zwei alte Prompts gibst, baue ich dir sofort die Analyzer-Ausgabe, den Optimized v1 und die Verifier-Ergebnisse in voller Länge — genau nach diesem Playbook.