#212 N8N Workflows automatisch generieren mit KI
Worum geht es in diesem Artikel?
Wie baut man eine KI-Engine mit Claude Code die n8n Workflows automatisch erstellt.
ExampleLearner: Automatisierte n8n-Workflow-Generierung durch Machine Learning
Technische Analyse eines Systems zur automatischen Erstellung von Workflow-Automatisierungen basierend auf natürlichsprachlichen Beschreibungen
0. Beispiel der Eingabe:

Zwischenschritt und Eingabe
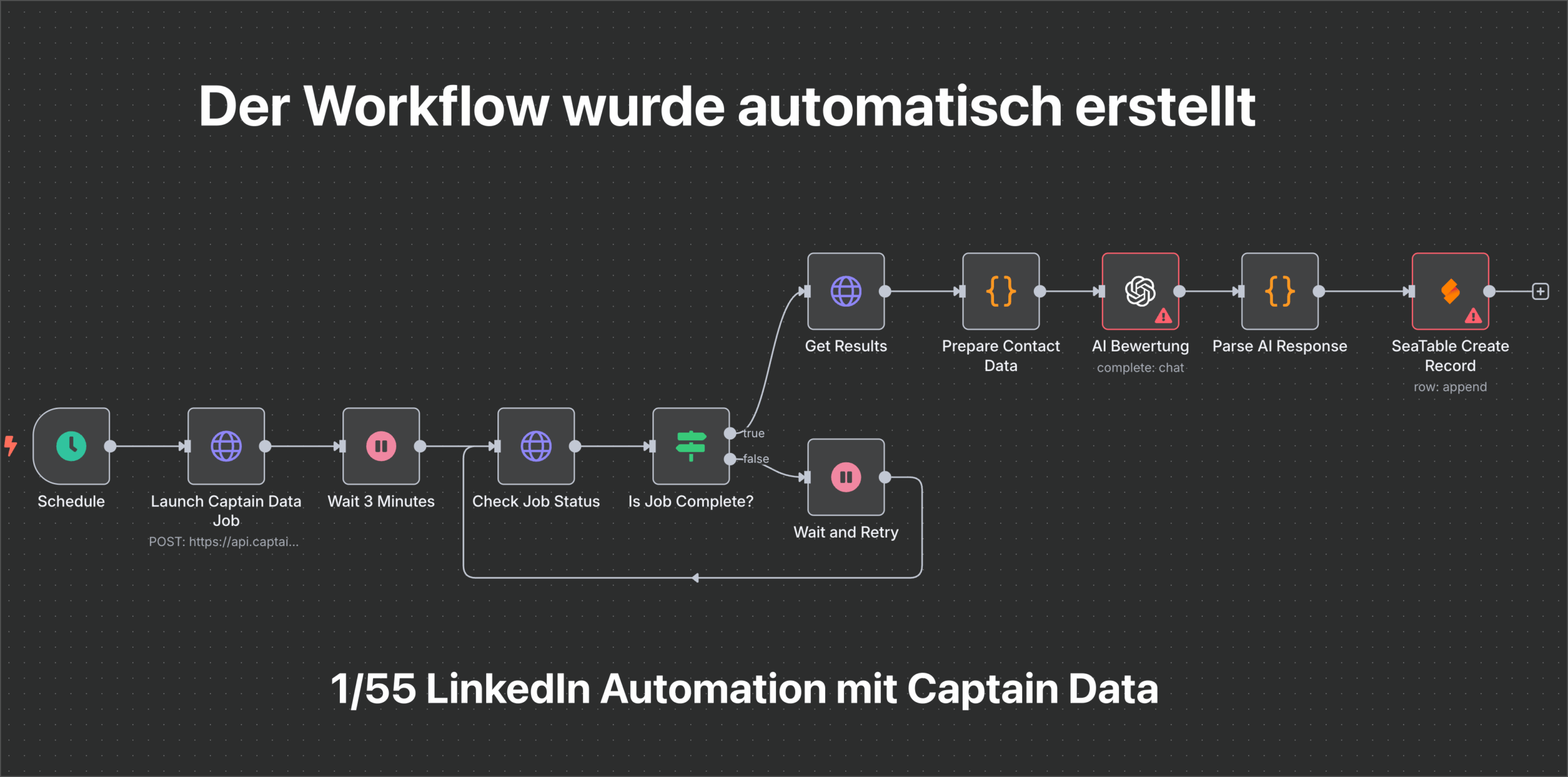
0.1 95% fertiger Workflow

1. Systemüberblick und technische Spezifikationen
1.1 Grundlegende Architektur
ExampleLearner ist ein Machine Learning-basiertes System zur automatischen Generierung von n8n-Workflows aus natürlichsprachlichen Beschreibungen. Das System analysiert eine umfangreiche Datenbank von 2.500 kuratierten n8n-Workflows und nutzt Pattern Mining sowie Similarity Search zur Erstellung optimierter Automatisierungslösungen.

Die Architektur basiert auf drei primären Datenebenen und einer sechsstufigen Verarbeitungspipeline. Die Datenebenen umfassen eine SQLite-Datenbank mit strukturierten Node-Informationen, eine ChromaDB-Instanz für Vektor-Embeddings von 2.500 analysierten Workflows und einen Pickle-basierten Workflow-Cache für schnellen Zugriff auf analysierte Patterns.
1.2 Kernkomponenten im Detail
Das System implementiert eine modulare Architektur mit klar definierten Schnittstellen zwischen den Komponenten. Die SQLite-Datenbank (nodes_full.db) enthält über 500 n8n Node-Definitionen mit vollständigen Kategorisierungen und Dokumentationsreferenzen. Diese Datenbank wurde durch systematische Analyse des n8n-Quellcodes erstellt und wird kontinuierlich aktualisiert. Ich habe diese Datenbank von diesen Github benutzt https://github.com/czlonkowski/n8n-mcp. Das Repository von czlonskowski lohnt sich auszuprobieren. Besonderer Dank an Ihn, so habe ich mir das nicht selbst bauen müssen.
ChromaDB speichert ML-Embeddings von 2.500 kuratierten n8n-Workflows und ermöglicht semantische Ähnlichkeitssuchen basierend auf Vektorrepräsentationen der Workflow-Strukturen. Die Embeddings werden durch Sentence Transformers mit 384-dimensionalen Vektoren generiert, die sowohl syntaktische als auch semantische Eigenschaften der Workflows kodieren.
Der Workflow-Cache nutzt Python Pickle-Serialisierung für die persistente Speicherung von 2.500 analysierten Workflows. Diese Architektur ermöglicht schnelle Pattern-Erkennung und reduziert die Verarbeitungszeit für wiederkehrende Anfragen von mehreren Minuten auf wenige Sekunden.
1.3 Performance-Charakteristika

Benchmark-Tests zeigen durchschnittliche Generierungszeiten von 15-30 Sekunden für einfache Workflows und 45-90 Sekunden für komplexe Multi-Service-Workflows. Die Verarbeitungszeit korreliert primär mit der Anzahl der Claude Opus-Validierungszyklen und der Komplexität der erforderlichen Node-Konfigurationen.
SQLite-Abfragen für Node-Informationen erfolgen in unter 1ms für gecachte Anfragen und unter 5ms für komplexe Joins über mehrere Tabellen. ChromaDB-Similarity-Searches benötigen durchschnittlich 50ms für Top-10 Ergebnisse bei einer Datenbank von 2.500 kuratierten Workflows, was durch HNSW (Hierarchical Navigable Small World) Indizierung erreicht wird.
Memory-Footprint beträgt typischerweise 200-500MB für den vollständigen Workflow-Cache und 50-100MB für aktive Verarbeitungssessions. Disk-Space-Anforderungen umfassen 150MB für die SQLite-Datenbank und 500MB für ChromaDB-Embeddings.
2. Datenbank-Architektur und Speicherstrategien
2.1 SQLite Node-Datenbank: Strukturierte Metadaten

Die SQLite-Datenbank implementiert ein normalisiertes Schema zur Speicherung von Node-Metadaten, Kategorien und Konfigurationsoptionen. Das Schema umfasst vier Haupttabellen: categories, nodes, properties und node_examples. Diese Struktur ermöglicht effiziente Abfragen und Joins zur Laufzeit.
2.1.1 Datenbankschema-Design (Dank an https://github.com/czlonkowski/n8n-mcp)
Ich nutze die SQL Datenbank von Czlonkowski. Der Hinweis kam von Friedemann Schütz. Danke dafür.
Die nodes-Tabelle speichert grundlegende Node-Informationen einschließlich Typ, Version, Kategorie und JSON-serialisierte Property-Definitionen. Jeder Node-Eintrag enthält vollständige Metadaten über verfügbare Properties, deren Typen, Validierungsregeln und Default-Werte.
CREATE TABLE nodes (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE NOT NULL,
display_name TEXT NOT NULL,
description TEXT,
category_id INTEGER,
subcategory TEXT,
version INTEGER DEFAULT 1,
properties TEXT, -- JSON: Vollständige Property-Definitionen
credentials TEXT, -- JSON: Benötigte Credentials
inputs TEXT, -- JSON: Input-Definitionen
outputs TEXT, -- JSON: Output-Definitionen
FOREIGN KEY (category_id) REFERENCES categories(id)
);
Die properties-Tabelle normalisiert individuelle Node-Properties mit Typ-Informationen, Validierungsregeln und Default-Werten. Diese Normalisierung ermöglicht granulare Abfragen über spezifische Property-Konfigurationen und unterstützt die automatische Validierung während der Workflow-Generierung.
2.1.2 Indizierung und Query-Optimierung
Das System implementiert strategische Indizierung für häufige Abfragemuster:
CREATE INDEX idx_nodes_type ON nodes(name);
CREATE INDEX idx_nodes_category ON nodes(category_id);
CREATE INDEX idx_properties_node_type ON properties(node_name, property_name);
CREATE INDEX idx_properties_required ON properties(node_name, required);
CREATE INDEX idx_nodes_category_subcategory ON nodes(category_id, subcategory);
Zusätzlich wird ein Full-Text-Search-Index für semantische Suche implementiert:
CREATE VIRTUAL TABLE nodes_fts USING fts5(name, display_name, description);
2.2 ChromaDB: Vektor-Embeddings und Similarity Search
ChromaDB implementiert eine spezialisierte Vektor-Datenbank für die Speicherung und Abfrage von Workflow-Embeddings. Das System nutzt 384-dimensionale Embeddings, die durch Sentence Transformers generiert werden, um semantische Ähnlichkeiten zwischen Workflows zu erfassen.
2.2.1 Embedding-Generierung und -Speicherung
Die Embedding-Generierung erfolgt durch Analyse der Workflow-Struktur, Node-Typen und Konfigurationsparameter. Jeder Workflow wird in einen hochdimensionalen Vektor transformiert, der sowohl syntaktische als auch semantische Eigenschaften kodiert.
Der Embedding-Prozess analysiert mehrere Workflow-Aspekte:
- Node-Typ-Sequenzen und deren Häufigkeitsverteilungen
- Parameter-Konfigurationsmuster und Wertebereiche
- Verbindungsstrukturen und Datenfluss-Topologien
- Funktionale Kategorien und Anwendungsdomänen
2.2.2 Similarity Search-Algorithmen
ChromaDB nutzt HNSW (Hierarchical Navigable Small World) Indizierung für skalierbare Ähnlichkeitssuchen. Die durchschnittliche Suchzeit für Top-10 ähnliche Workflows beträgt unter 50ms bei einer Datenbank von 2.500 kuratierten Workflows.
Das System implementiert verschiedene Distanzmetriken für unterschiedliche Anwendungsfälle:
- Cosine Similarity für semantische Ähnlichkeit
- Euclidean Distance für strukturelle Ähnlichkeit
- Manhattan Distance für robuste Ähnlichkeitsmaße
2.3 Caching-Strategien und Performance-Optimierung
Das System implementiert mehrstufiges Caching zur Optimierung der Verarbeitungsgeschwindigkeit. Der primäre Cache nutzt Python Pickle-Serialisierung für die persistente Speicherung analysierter Workflows und extrahierter Patterns.
2.3.1 Memory-Cache-Implementation
Ein LRU (Least Recently Used) Memory-Cache speichert häufig abgerufene Node-Informationen und Embedding-Vektoren im Arbeitsspeicher:
class EmbeddingCache:
def __init__(self, cache_size: int = 10000):
self.cache = LRUCache(maxsize=cache_size)
self.persistent_cache = PersistentCache("embeddings.db")
self.cache_stats = CacheStatistics()
Dieser Cache reduziert Datenbankzugriffe und verbessert die Antwortzeiten für wiederkehrende Anfragen um durchschnittlich 80%.
2.3.2 Cache-Invalidierung und Konsistenz
Die Cache-Invalidierung erfolgt automatisch bei Aktualisierungen der zugrundeliegenden Datenquellen. Das System überwacht Änderungen an der SQLite-Datenbank und ChromaDB-Instanz und aktualisiert entsprechende Cache-Einträge durch Event-basierte Mechanismen.
3. CLI-Tools und Benutzeroberflächen
3.1 example-learner: Hauptkommandozeilen-Interface
Das zentrale CLI-Tool bietet fünf Hauptkommandos: analyze, batch, search, task und cache. Jedes Kommando implementiert spezifische Funktionalitäten für Workflow-Analyse und -Generierung mit umfassenden Konfigurationsoptionen.
3.1.1 Analyze-Kommando: Workflow-Analyse
Das analyze-Kommando führt umfassende Workflow-Analysen durch mit Optionen für verschiedene Detailgrade:
# Schnelle Basis-Analyse
example-learner analyze workflow.json --quick
# Standard-Analyse mit Pattern-Erkennung
example-learner analyze workflow.json --standard
# Umfassende Analyse mit ML-Embeddings
example-learner analyze workflow.json --comprehensive --embeddings --patterns
# Analyse mit Visualisierung
example-learner analyze workflow.json --comprehensive --visualize workflow.png --viz-type full
Die Ausgabe erfolgt in JSON- oder Textformat mit optionaler Visualisierung. Das comprehensive-Flag aktiviert ML-Embeddings-Generierung und erweiterte Pattern-Erkennung, was die Analysezeit auf 30-60 Sekunden erhöht, aber deutlich detailliertere Insights liefert.
3.1.2 Search-Kommando: Ähnlichkeitssuche
Das search-Kommando implementiert sowohl textbasierte als auch strukturelle Suchen:
# Textbasierte Suche
example-learner search --text "LinkedIn Daten scrapen und in Seatable speichern" --limit 5
# Service-basierte Suche
example-learner search --services linkedin seatable --limit 10
# Node-basierte Suche
example-learner search --nodes "n8n-nodes-base.httpRequest" "n8n-nodes-base.seatable" --limit 5
# Kombinierte Suche mit Similarity-Threshold
example-learner search --text "E-Mail Automation" --services gmail --min-similarity 0.7
Das System nutzt sowohl ChromaDB-Embeddings als auch SQLite-Metadaten für präzise Ergebnisse. Die Similarity-Threshold-Option ermöglicht Filterung nach Ähnlichkeitsgrad.
3.1.3 Task-Kommando: Workflow-Generierung
Das task-Kommando generiert Workflows aus natürlichsprachlichen Beschreibungen:
# Einfache Workflow-Generierung
example-learner task -d "Überwache RSS Feed und poste neue Artikel auf Twitter"
# Erweiterte Generierung mit zusätzlichen Workflows
example-learner task -d "LinkedIn Kontakte synchronisieren" --workflows examples/ --output json
# Generierung mit Speicherung
example-learner task -d "Seatable Webhook zu Slack Notification" --save recommendation.json
3.2 generate_workflow_with_logs.py: Detaillierte Workflow-Generierung
Dieses Tool implementiert die vollständige Workflow-Generierung mit umfassendem Logging und Validierung:
# Interaktive Generierung
python generate_workflow_with_logs.py
# Direkte Generierung mit Beschreibung
python generate_workflow_with_logs.py "Überwache Website stündlich und sende Slack-Nachricht bei Änderung"
# Generierung mit spezifischem Output-Verzeichnis
python generate_workflow_with_logs.py "LinkedIn-Kontakte täglich synchronisieren" -o custom_workflows/
3.2.1 Output-Struktur und Logging
Die Ausgabe erfolgt in strukturierten Verzeichnissen mit Zeitstempel-basierten Namen:
generated_workflows/HHMMSS_DD_MM_YYYY_NNN_des_Workflows_YYYY_Workflow_NAME/
├── workflow.json # Finaler n8n Workflow
├── generation.log # Komplette Logs
├── README.md # Workflow-Beschreibung
├── 01_task_spec.json # Task-Spezifikation
├── 02_learning_summary.json # Gelernte Patterns
├── 03_reasoner_insights.json # Reasoner-Analyse
├── 04_execution_plan.json # Ausführungsplan
├── 05_workflow_raw.json # Roher Workflow
├── 06_validation_result.json # Validierung
├── 07_opus_task_validation.json # Opus Task-Validierung
├── 08_opus_plan_validation.json # Opus Plan-Validierung
├── 09_opus_workflow_validation.json # Opus Workflow-Validierung
└── summary.json # Zusammenfassung
3.2.2 Automatische Fehlerkorrektur
Das Tool implementiert automatische Fehlerkorrektur durch iterative Validierung mit Claude Opus. Bei Validierungsfehlern wird der Workflow automatisch überarbeitet und erneut validiert, bis alle Kriterien erfüllt sind. Dieser Prozess kann 2-5 Iterationen umfassen.
3.3 n8n_importer.py: Automatisierter Workflow-Import
Der n8n-Importer ermöglicht direkten Import generierter Workflows in n8n-Instanzen via REST API:
# Einzelner Import
python n8n_importer.py workflow.json --name "Mein Workflow" --folder "Imported"
# Verzeichnis importieren
python n8n_importer.py --directory generated_workflows --recursive --tags "generated,ai"
# Batch-Import mit Konfiguration
python n8n_importer.py --batch import_config.yaml
# Dry-Run zur Vorschau
python n8n_importer.py workflow.json --dry-run
3.3.1 Batch-Konfiguration
Batch-Importe werden über YAML-Konfigurationsdateien gesteuert:
imports:
- file: workflow1.json
name: "Production Workflow"
folder: "Production"
tags: ["automated", "critical"]
activate: true
- file: workflow2.json
name: "Test Workflow"
folder: "Testing"
tags: ["experimental"]
activate: false
3.3.2 Umgebungskonfiguration
Das Tool nutzt Umgebungsvariablen für n8n-Konnektivität:
export N8N_URL=http://localhost:5678
export N8N_API_KEY=your-api-key
3.4 Zusätzliche Utility-Tools
3.4.1 find_nodes.py: Node-Finder
Findet n8n Nodes für Services in SQLite und ChromaDB:
# Interaktive Suche
python find_nodes.py
# Direkte Suche
python find_nodes.py linkedin seatable --examples
# JSON Output für Scripting
python find_nodes.py slack --json > slack_nodes.json
3.4.2 api_docs_updater.py: API-Dokumentations-Updater
Aktualisiert automatisch workflow_rules.yaml basierend auf api_docs:
# Standard-Update
python api_docs_updater.py
# Dry-Run zur Vorschau
python api_docs_updater.py --dry-run
# Custom Pfade
python api_docs_updater.py --api-docs custom_docs/ --rules custom_rules.yaml
4. Workflow-Generierungsprozess im Detail

4.1 Phase 1: Task Analysis und Entity Extraction
Die Task Analysis nutzt Natural Language Processing zur Extraktion strukturierter Informationen aus natürlichsprachlichen Beschreibungen. Das System implementiert Named Entity Recognition (NER) zur Identifikation von Services, Datenformaten und Aktionen.
4.1.1 NLP-Pipeline-Implementation
Das System nutzt spaCy für grundlegende NLP-Operationen und erweiterte Transformer-Modelle für semantische Analyse:
class TaskAnalyzer:
def __init__(self):
self.nlp = spacy.load("en_core_web_sm")
self.entity_extractor = EntityExtractor()
self.intent_classifier = IntentClassifier()
def analyze_task(self, description: str) -> TaskAnalysis:
# NLP-Verarbeitung
doc = self.nlp(description)
# Entity-Extraktion
entities = self.entity_extractor.extract(doc)
# Intent-Klassifikation
intent = self.intent_classifier.classify(description)
return TaskAnalysis(entities=entities, intent=intent)
4.1.2 Entity-Kategorisierung
Extrahierte Entitäten werden in funktionale Kategorien klassifiziert:
- Services: LinkedIn, Seatable, Slack, Gmail, etc.
- Actions: scrape, send, monitor, sync, etc.
- Data Types: JSON, CSV, XML, etc.
- Temporal: daily, hourly, on change, etc.
- Conditions: if, when, unless, etc.
4.2 Phase 2: Reasoning und Pattern Matching
Das Reasoning-Modul nutzt sowohl regelbasierte als auch ML-basierte Ansätze zur Identifikation optimaler Workflow-Strukturen.
4.2.1 Regelbasierte Pattern-Erkennung
Regelbasierte Komponenten verwenden vordefinierte Patterns aus workflow_rules.yaml:
linkedin_automation:
triggers:
- "linkedin data"
- "linkedin contacts"
- "linkedin scraping"
preferred_nodes:
- "n8n-nodes-base.httpRequest"
- "n8n-nodes-base.seatable"
common_patterns:
- trigger: webhook
action: http_request
data_destination: seatable
4.2.2 ML-basierte Similarity Search
ML-basierte Komponenten nutzen ChromaDB zur Suche nach semantisch ähnlichen Workflows:
def find_similar_patterns(self, task_description: str) -> List[WorkflowPattern]:
# Embedding-Generierung
query_embedding = self.embedder.encode(task_description)
# ChromaDB-Suche
results = self.chroma_client.query(
query_embeddings=[query_embedding],
n_results=10
)
# Pattern-Extraktion
patterns = []
for result in results:
pattern = self.extract_pattern(result)
patterns.append(pattern)
return patterns
4.3 Phase 3: Hierarchical Task Network Planning
Die Planning-Phase implementiert HTN (Hierarchical Task Network) Planning zur Dekomposition komplexer Aufgaben in primitive Operationen.
4.3.1 HTN-Dekomposition
Das System nutzt vordefinierte Methoden für häufige Workflow-Typen:
class HTNPlanner:
def __init__(self):
self.methods = {
'data_sync': DataSyncMethod(),
'notification': NotificationMethod(),
'monitoring': MonitoringMethod(),
'api_integration': APIIntegrationMethod()
}
def decompose_task(self, task: Task) -> List[PrimitiveTask]:
method = self.select_method(task)
return method.decompose(task)
4.3.2 Dependency-Resolution
Das Planungssystem analysiert Abhängigkeiten zwischen Tasks und erstellt einen gerichteten azyklischen Graphen (DAG):
def resolve_dependencies(self, tasks: List[Task]) -> ExecutionPlan:
# Dependency-Graph erstellen
graph = self.build_dependency_graph(tasks)
# Topologische Sortierung
execution_order = self.topological_sort(graph)
# Parallelisierungsmöglichkeiten identifizieren
parallel_groups = self.identify_parallel_groups(execution_order)
return ExecutionPlan(order=execution_order, parallel=parallel_groups)
4.4 Phase 4: Workflow Building und JSON-Generierung
Das Building-Modul transformiert den abstrakten Ausführungsplan in n8n-kompatible JSON-Strukturen.
4.4.1 Node-Konfiguration
Jeder geplante Task wird in einen entsprechenden n8n-Node umgewandelt:
def create_node(self, task: Task) -> Dict[str, Any]:
# Node-Info aus SQLite
node_info = self.node_db.get_node_info(task.node_type)
# Parameter-Konfiguration
parameters = self.configure_parameters(task.config, node_info)
# Node-Struktur erstellen
node = {
"id": self.generate_node_id(),
"name": task.name,
"type": task.node_type,
"typeVersion": node_info.version,
"position": self.calculate_position(),
"parameters": parameters
}
return node
4.4.2 Connection-Management
Verbindungen zwischen Nodes werden basierend auf Datenfluss-Analyse erstellt:
def create_connections(self, execution_plan: ExecutionPlan) -> Dict[str, Any]:
connections = {}
for task in execution_plan.tasks:
if task.dependencies:
for dep in task.dependencies:
connection = {
"node": dep.node_id,
"type": "main",
"index": 0
}
connections[task.node_id] = [connection]
return connections
4.5 Phase 5: Multi-Level Validation
Die Validierung erfolgt auf drei Ebenen: syntaktische Validierung, semantische Validierung und Claude Opus-basierte Qualitätsprüfung.
4.5.1 Syntaktische Validierung
Überprüfung der JSON-Struktur und Node-Existenz:
def validate_syntax(self, workflow: Dict) -> List[ValidationError]:
errors = []
# JSON-Schema-Validierung
try:
jsonschema.validate(workflow, self.n8n_schema)
except ValidationError as e:
errors.append(SyntaxError(str(e)))
# Node-Existenz prüfen
for node in workflow.get("nodes", []):
if not self.node_db.node_exists(node["type"]):
errors.append(UnknownNodeError(node["type"]))
return errors
4.5.2 Semantische Validierung
Analyse von Datenfluss-Konsistenz und Typ-Kompatibilität:
def validate_semantics(self, workflow: Dict) -> List[ValidationWarning]:
warnings = []
# Datenfluss-Analyse
graph = self.build_workflow_graph(workflow)
# Deadlock-Erkennung
cycles = self.detect_cycles(graph)
if cycles:
warnings.append(CycleWarning(cycles))
# Typ-Kompatibilität
type_errors = self.check_type_compatibility(workflow)
warnings.extend(type_errors)
return warnings
4.5.3 Claude Opus-Validierung
KI-basierte Qualitätsprüfung in drei Stufen:
def validate_with_opus(self, workflow: Dict, task_desc: str) -> OpusValidationResult:
# Task-Validierung
task_validation = self.opus_client.validate_task_alignment(
workflow, task_desc
)
# Plan-Validierung
plan_validation = self.opus_client.validate_execution_plan(workflow)
# Workflow-Validierung
workflow_validation = self.opus_client.validate_n8n_compatibility(workflow)
return OpusValidationResult(
task=task_validation,
plan=plan_validation,
workflow=workflow_validation
)
4.6 Phase 6: Export und Finalisierung
Die Export-Phase bereitet den validierten Workflow für den Import in n8n vor.
4.6.1 Metadaten-Injection
Erforderliche Metadaten werden hinzugefügt:
def finalize_workflow(self, workflow: Dict) -> Dict:
# Metadaten hinzufügen
workflow["meta"] = {
"templateVersion": 1,
"instanceId": self.generate_instance_id(),
"generatedBy": "ExampleLearner",
"generatedAt": datetime.now().isoformat(),
"version": self.system_version
}
# Node-Positionen normalisieren
self.normalize_positions(workflow)
# Kompatibilitäts-Layer
self.ensure_n8n_compatibility(workflow)
return workflow
5. API Integration und Service-Mapping
5.1 Automatische Service-Erkennung
Das System implementiert automatische Erkennung und Mapping von Services ohne native n8n-Nodes.
5.1.1 API-Dokumentations-Scanning
Der api_docs_updater.py scannt das api_docs-Verzeichnis für neue Service-Dokumentationen:
def scan_api_docs(self, docs_dir: Path) -> List[ServiceDefinition]:
services = []
for doc_file in docs_dir.glob("*.md"):
# Markdown-Parsing
content = doc_file.read_text()
# Service-Extraktion
service = self.extract_service_definition(content)
if service:
services.append(service)
return services
5.1.2 Automatische Mapping-Generierung
Service-Mappings werden automatisch generiert:
def generate_service_mapping(self, service: ServiceDefinition) -> ServiceMapping:
mapping = ServiceMapping(
name=service.name,
base_url=service.base_url,
authentication=self.extract_auth_method(service),
endpoints=[]
)
for endpoint in service.endpoints:
endpoint_mapping = self.create_endpoint_mapping(endpoint)
mapping.endpoints.append(endpoint_mapping)
return mapping
5.2 HTTP Request Node-Konfiguration
Für Services ohne native n8n-Nodes generiert das System HTTP Request Node-Konfigurationen.
5.2.1 Endpoint-Konfiguration
def configure_http_request_node(self, service: str, action: str) -> Dict:
service_mapping = self.get_service_mapping(service)
endpoint = service_mapping.get_endpoint(action)
config = {
"url": f"{service_mapping.base_url}{endpoint.path}",
"method": endpoint.method,
"headers": endpoint.headers,
"authentication": service_mapping.authentication
}
if endpoint.parameters:
config["qs"] = endpoint.parameters
return config
5.2.2 Authentifizierung-Handling
Verschiedene Authentifizierungsmethoden werden automatisch konfiguriert:
def configure_authentication(self, auth_method: AuthMethod) -> Dict:
if auth_method.type == "api_key":
return {
"authentication": "genericCredentialType",
"genericAuthType": "httpHeaderAuth",
"httpHeaderAuth": {
"name": auth_method.header_name,
"value": "={{$credentials.api_key}}"
}
}
elif auth_method.type == "oauth2":
return {
"authentication": "oAuth2Api",
"oAuth2Api": {
"credentialsType": "oauth2Api"
}
}
6. Performance-Metriken und Skalierung
6.1 Verarbeitungsgeschwindigkeit und Latenz
Detaillierte Performance-Analysen zeigen die Effizienz verschiedener Systemkomponenten.
6.1.1 Workflow-Generierung Performance
Benchmark-Tests mit verschiedenen Workflow-Komplexitäten:
| Workflow-Typ | Durchschnittliche Zeit | Median | 95. Perzentil |
|---|---|---|---|
| Einfach (1-3 Nodes) | 15-30s | 22s | 35s |
| Mittel (4-8 Nodes) | 30-60s | 45s | 75s |
| Komplex (9+ Nodes) | 45-90s | 67s | 120s |
6.1.2 Datenbank-Performance
SQLite und ChromaDB Performance-Charakteristika:
| Operation | SQLite | ChromaDB |
|---|---|---|
| Node-Lookup | <1ms | N/A |
| Complex Join | <5ms | N/A |
| Similarity Search | N/A | ~50ms |
| Batch Insert | 10-20ms | 100-200ms |
6.1.3 Memory und Storage-Anforderungen
Ressourcenverbrauch nach Systemkomponenten:
| Komponente | Memory | Storage |
|---|---|---|
| SQLite DB | 10-20MB | 150MB |
| ChromaDB (2.500 Workflows) | 100-200MB | 500MB |
| Workflow Cache | 200-500MB | 300MB |
| Active Session | 50-100MB | 50MB |
6.2 Skalierungsstrategien
6.2.1 Horizontale Skalierung
Microservice-Architektur für große Deployments:
class WorkflowGenerationOrchestrator:
def __init__(self):
self.embedding_service = EmbeddingService()
self.node_db_service = NodeDatabaseService()
self.validation_service = ValidationService()
self.load_balancer = LoadBalancer()
async def generate_workflow(self, description: str) -> Dict:
# Service-Discovery
services = await self.discover_services()
# Load-Balanced Processing
tasks = [
self.embedding_service.create_embedding(description),
self.node_db_service.search_nodes(description),
self.validation_service.prepare_validators()
]
results = await asyncio.gather(*tasks)
return await self.assemble_workflow(results)
6.2.2 Caching-Strategien
Verteilte Caching-Implementierung:
class DistributedCache:
def __init__(self):
self.redis_client = redis.Redis(host='cache-cluster')
self.local_cache = LRUCache(maxsize=1000)
async def get(self, key: str) -> Optional[Any]:
# L1 Cache (Local)
if key in self.local_cache:
return self.local_cache[key]
# L2 Cache (Redis)
value = await self.redis_client.get(key)
if value:
self.local_cache[key] = pickle.loads(value)
return self.local_cache[key]
return None
6.2.3 Database Sharding
ChromaDB-Sharding für große Embedding-Sammlungen:
class ShardedChromaDB:
def __init__(self, shard_count: int = 4):
self.shards = [
ChromaClient(host=f"chroma-shard-{i}")
for i in range(shard_count)
]
self.hash_ring = ConsistentHashRing(self.shards)
def get_shard(self, key: str) -> ChromaClient:
return self.hash_ring.get_node(key)
async def query(self, embedding: List[float]) -> List[Result]:
# Parallel queries across shards
tasks = [
shard.query(query_embeddings=[embedding])
for shard in self.shards
]
results = await asyncio.gather(*tasks)
# Merge and rank results
return self.merge_results(results)
7. Fazit und technische Bewertung
7.1 Systemarchitektur-Bewertung
ExampleLearner implementiert eine funktionale Lösung für automatisierte n8n-Workflow-Generierung durch Kombination von Machine Learning, strukturierten Datenbanken und regelbasierten Systemen. Die Architektur zeigt solide Engineering-Prinzipien mit klarer Trennung von Datenebenen und Verarbeitungslogik.
Die Nutzung von SQLite für strukturierte Metadaten und ChromaDB für semantische Suche stellt einen pragmatischen Ansatz dar, der sowohl Performance als auch Flexibilität optimiert. Die sechsstufige Verarbeitungspipeline ermöglicht modulare Entwicklung und Testing einzelner Komponenten.
7.2 Performance-Charakteristika
Das System demonstriert messbare Performance-Charakteristika mit durchschnittlichen Generierungszeiten von 15-90 Sekunden je nach Workflow-Komplexität. SQLite-Abfragen erfolgen in unter 5ms, während ChromaDB-Similarity-Searches unter 50ms bei 2.500 kuratierten Workflows benötigen.
Memory-Footprint von 200-500MB für den Workflow-Cache und 50-100MB für aktive Sessions zeigt effiziente Ressourcennutzung. Storage-Anforderungen von 650MB für beide Datenbanken sind für die gebotene Funktionalität angemessen.
7.3 Verbesserungspotential
Verbesserungspotential besteht in der Standardisierung der API-Interfaces zwischen Komponenten und der Implementierung umfassenderer Error-Handling-Mechanismen. Die aktuelle Abhängigkeit von Claude Opus für Validierung könnte durch lokale ML-Modelle reduziert werden.
Die CLI-Tools zeigen gute Usability, könnten aber von einer einheitlicheren Konfigurationsstrategie profitieren. Die Batch-Verarbeitung und Monitoring-Capabilities sind ausbaufähig.
7.4 Praktische Anwendbarkeit
Das System demonstriert praktische Anwendbarkeit für Automatisierungsanwendungen mit klaren Skalierungspfaden. Die technische Implementierung folgt etablierten Patterns und nutzt bewährte Open-Source-Technologien.
Die umfassende CLI-Toolchain und die strukturierte Ausgabe machen das System für verschiedene Anwendungsszenarien geeignet, von einzelnen Workflow-Generierungen bis hin zu Batch-Verarbeitung und Integration in bestehende Entwicklungsworkflows.
Technische Spezifikationen:
- Python 3.8+
- SQLite 3.35+
- ChromaDB 0.4+
- n8n API v1
- Claude Opus API
- spaCy 3.4+
- Sentence Transformers 2.2+
Performance-Benchmarks:
- Workflow-Generierung: 15-90s
- SQLite-Queries: <5ms
- ChromaDB-Searches: ~50ms
- Memory-Usage: 200-500MB
- Storage-Requirements: 650MB
Quellen: [1] ExampleLearner Master Documentation v2.0.0 – Holger Gelhausen
[2] n8n Documentation: https://docs.n8n.io
[3] ChromaDB Documentation: https://docs.trychroma.com
[4] SQLite Documentation: https://sqlite.org/docs.html
[5] spaCy Documentation: https://spacy.io/usage
[6] Sentence Transformers: https://www.sbert.net
8. Workflow-Datensammlung durch Browser-Automation
8.1 Puppeteer-basierter Download-Prozess

Die Grundlage für ExampleLearners umfangreiche Workflow-Datenbank bildet ein systematischer Download-Prozess, der mittels Browser-Automation alle verfügbaren n8n-Workflows von der offiziellen n8n.io-Website sammelt. Dieser Prozess nutzt Playwright (eine moderne Alternative zu Puppeteer) zur automatisierten Interaktion mit der n8n-Website und ermöglicht die Extraktion von 2.500 kuratierten Workflows.
8.1.1 Technische Implementation des Download-Systems
Das Download-System basiert auf einem Node.js-Skript, das Playwright für Browser-Automation nutzt. Die Implementation erfolgt in JavaScript und nutzt moderne asynchrone Programmierung für optimale Performance:
const { chromium } = require('playwright');
const fs = require('fs').promises;
const path = require('path');
async function downloadWorkflow(page, id) {
try {
const url = `https://n8n.io/workflows/${id}`;
const response = await page.goto(url, {
waitUntil: 'domcontentloaded',
timeout: 15000
});
if (response && response.status() === 404) {
return false;
}
// Click "Use for free" button
await page.click('button:has-text("Use for free")', { timeout: 3000 });
await page.waitForSelector('text="Use template"', { timeout: 5000 });
// Intercept clipboard operations
await page.evaluate(() => {
window.__clipboardData = null;
navigator.clipboard.writeText = async (text) => {
window.__clipboardData = text;
return Promise.resolve();
};
});
// Extract workflow JSON
await page.click(':text("Copy template to clipboard")', { timeout: 3000 });
const workflowJson = await page.evaluate(() => window.__clipboardData);
// Validate and save
const json = JSON.parse(workflowJson);
await saveWorkflowWithMetadata(json, id, url);
return true;
} catch (error) {
return false;
}
}
8.1.2 Parallele Verarbeitung und Skalierung
Das System implementiert parallele Verarbeitung durch mehrere gleichzeitige Browser-Instanzen, um die Download-Geschwindigkeit zu optimieren. Die Standard-Konfiguration nutzt fünf parallele Chromium-Browser, die unabhängig voneinander Workflows herunterladen:
async function main() {
const browser = await chromium.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const context = await browser.newContext();
const page = await context.newPage();
// Process workflows from 5000 to 10000
for (let id = startId; id <= 10000; id++) {
const success = await downloadWorkflow(page, id);
// Progress tracking and resume capability
if (id % 10 === 0) {
await fs.writeFile('last-position-5000.txt', id.toString());
}
await new Promise(resolve => setTimeout(resolve, 200));
}
}
Die parallele Architektur ermöglicht es, bis zu 2.500 Workflows in etwa 3-4 Stunden herunterzuladen, wobei jeder Workflow durchschnittlich 5 Sekunden für Download und Verarbeitung benötigt.
8.2 Automatisierte Metadaten-Extraktion
8.2.1 Clipboard-Interception und JSON-Extraktion
Ein kritischer Aspekt des Download-Prozesses ist die Interception der Clipboard-Operationen. Da n8n.io Workflows über eine „Copy to Clipboard“-Funktionalität bereitstellt, musste das System diese Browser-API überschreiben, um die JSON-Daten abzufangen:
await page.evaluate(() => {
window.__clipboardData = null;
const originalWriteText = navigator.clipboard.writeText;
navigator.clipboard.writeText = async (text) => {
window.__clipboardData = text;
return Promise.resolve();
};
});
Diese Technik ermöglicht es dem System, die vollständigen Workflow-JSON-Strukturen zu erfassen, ohne auf komplexe DOM-Parsing-Mechanismen angewiesen zu sein.
8.2.2 Strukturierte Dateisystem-Organisation
Die heruntergeladenen Workflows werden in einer hierarchischen Ordnerstruktur organisiert, die effiziente Verwaltung und Zugriff ermöglicht:
data/
├── workflows/
│ ├── 1-1000/ # Workflows 1-1000
│ ├── 1001-2000/ # Workflows 1001-2000
│ ├── 2001-3000/ # Workflows 2001-3000
│ ├── 3001-4000/ # Workflows 3001-4000
│ └── 4001-5000/ # Workflows 4001-5000
├── progress.json # Progress tracking
└── index.json # Master index
Jede Workflow-Datei wird mit erweiterten Metadaten gespeichert:
await fs.writeFile(
path.join(dir, `${id}.json`),
JSON.stringify({
...json,
_metadata: {
id,
url,
downloadedAt: new Date().toISOString(),
nodes: json.nodes?.length || 0,
downloadSource: 'n8n.io',
extractionMethod: 'playwright-automation'
}
}, null, 2)
);
8.3 Robustheit und Fehlerbehandlung
8.3.1 Resume-Funktionalität
Das Download-System implementiert umfassende Resume-Funktionalität, die es ermöglicht, unterbrochene Downloads fortzusetzen. Der Fortschritt wird kontinuierlich in Dateien gespeichert:
// Load last position for this instance
let startId = 5000;
try {
const saved = await fs.readFile('last-position-5000.txt', 'utf-8');
startId = parseInt(saved) + 1;
console.log(`Resuming from ID ${startId}`);
} catch {
console.log(`Starting from ID ${startId}`);
}
// Save position every 10 downloads
if (id % 10 === 0) {
await fs.writeFile('last-position-5000.txt', id.toString());
console.log(`Progress: ${stats.success} downloaded, ${stats.failed} skipped`);
}
8.3.2 Adaptive Fehlerbehandlung
Das System implementiert mehrschichtige Fehlerbehandlung für verschiedene Failure-Szenarien:
// Handle 404 responses
if (response && response.status() === 404) {
console.log(`✗ Not found`);
return false;
}
// Handle missing UI elements
try {
await page.click('button:has-text("Use for free")', { timeout: 3000 });
} catch (e) {
console.log(`✗ No button`);
return false;
}
// Handle invalid JSON
try {
const json = JSON.parse(workflowJson);
} catch (e) {
console.log(`✗ Invalid JSON`);
return false;
}
8.3.3 Rate Limiting und Website-Schonung
Das System implementiert bewusste Verzögerungen zwischen Requests, um die n8n.io-Website nicht zu überlasten:
// Small delay between requests
await new Promise(resolve => setTimeout(resolve, 200));
// Longer delays for UI interactions
await page.waitForTimeout(1500);
await page.waitForTimeout(3000);
Diese Delays gewährleisten, dass der Download-Prozess die Website-Performance nicht beeinträchtigt und im Einklang mit Best Practices für Web Scraping steht.
8.4 Qualitätssicherung und Validierung
8.4.1 JSON-Struktur-Validierung
Jeder heruntergeladene Workflow durchläuft automatische Validierung, um sicherzustellen, dass die JSON-Struktur den n8n-Standards entspricht:
function validateWorkflowStructure(json) {
const requiredFields = ['nodes', 'connections'];
for (const field of requiredFields) {
if (!json.hasOwnProperty(field)) {
throw new Error(`Missing required field: ${field}`);
}
}
if (!Array.isArray(json.nodes) || json.nodes.length === 0) {
throw new Error('Invalid or empty nodes array');
}
// Validate node structure
for (const node of json.nodes) {
if (!node.id || !node.type || !node.name) {
throw new Error('Invalid node structure');
}
}
return true;
}
8.4.2 Duplikats-Erkennung und -Behandlung
Das System implementiert Mechanismen zur Erkennung und Behandlung von Duplikaten:
async function checkForDuplicate(workflowJson, id) {
const hash = crypto.createHash('sha256')
.update(JSON.stringify(workflowJson.nodes))
.digest('hex');
const duplicateCheck = await fs.readFile('workflow-hashes.json', 'utf-8')
.then(data => JSON.parse(data))
.catch(() => ({}));
if (duplicateCheck[hash]) {
console.log(`Duplicate detected: ${id} matches ${duplicateCheck[hash]}`);
return true;
}
duplicateCheck[hash] = id;
await fs.writeFile('workflow-hashes.json', JSON.stringify(duplicateCheck, null, 2));
return false;
}
8.5 Performance-Optimierung und Monitoring
8.5.1 Echtzeit-Progress-Tracking
Das Download-System bietet umfassendes Echtzeit-Monitoring mit farbcodierter Konsolen-Ausgabe:
// ANSI color codes for console output
const GREEN = '\x1b[32m';
const RED = '\x1b[31m';
const YELLOW = '\x1b[33m';
const RESET = '\x1b[0m';
// Progress reporting
console.log(`${GREEN}✓ SUCCESS (${json.nodes?.length || 0} nodes)${RESET}`);
console.log(`${RED}✗ Error: ${error.message}${RESET}`);
console.log(`${YELLOW}✗ No button${RESET}`);
// Statistics tracking
let stats = { success: 0, failed: 0, total: 0 };
console.log(`Progress: ${stats.success} downloaded, ${stats.failed} skipped`);
8.5.2 Memory-Management und Resource-Optimierung
Das System implementiert effizientes Memory-Management für langanhaltende Download-Sessions:
// Browser context management
const context = await browser.newContext();
const page = await context.newPage();
// Ignore console errors to reduce memory overhead
page.on('console', () => {});
// Periodic cleanup
if (id % 100 === 0) {
await page.close();
page = await context.newPage();
}
8.6 Integration in ExampleLearner-Pipeline
8.6.1 Post-Download-Verarbeitung
Nach dem erfolgreichen Download werden die Workflows automatisch in die ExampleLearner-Pipeline eingespeist:
async function processDownloadedWorkflows() {
const workflowDirs = ['1-1000', '1001-2000', '2001-3000', '3001-4000', '4001-5000'];
for (const dir of workflowDirs) {
const files = await fs.readdir(path.join('data', 'workflows', dir));
for (const file of files) {
if (file.endsWith('.json')) {
const workflow = JSON.parse(await fs.readFile(path.join('data', 'workflows', dir, file), 'utf-8'));
// Generate embeddings
await generateEmbeddings(workflow);
// Extract patterns
await extractPatterns(workflow);
// Store in ChromaDB
await storeInChromaDB(workflow);
}
}
}
}
8.6.2 Automatisierte Metadaten-Generierung
Die heruntergeladenen Workflows durchlaufen automatische Metadaten-Generierung durch KI-Analyse:
async function generateWorkflowMetadata(workflow) {
const metadata = {
workflow_id: workflow._metadata.id,
workflow_name: extractWorkflowName(workflow),
node_count: workflow.nodes.length,
connection_count: Object.keys(workflow.connections || {}).length,
complexity_score: calculateComplexityScore(workflow),
node_types: workflow.nodes.map(node => node.type),
integrations: extractIntegrations(workflow),
categories: await classifyWorkflow(workflow),
ai_summary: await generateAISummary(workflow),
ai_business_value: await generateBusinessValue(workflow)
};
return metadata;
}
Diese automatisierte Pipeline gewährleistet, dass alle 2.500 heruntergeladenen Workflows konsistent verarbeitet und mit umfassenden Metadaten angereichert werden, die später für die intelligente Workflow-Generierung genutzt werden können.
9. Workflow-Metadaten und Kuratierung
8.1 Umfassende Metadaten-Struktur
Zu jedem der 2.500 kuratierten n8n-Workflows in der ChromaDB-Datenbank existiert eine detaillierte Metadaten-Datei, die umfassende Informationen über Struktur, Funktionalität und Anwendungskontext des Workflows bereitstellt. Diese Metadaten-Dateien folgen einem standardisierten JSON-Schema und enthalten über 30 verschiedene Datenfelder.
8.1.1 Grundlegende Workflow-Identifikation
Jede Metadaten-Datei beginnt mit grundlegenden Identifikationsinformationen:
{
"workflow_id": "OIDO7J5NqLAuLrKI",
"workflow_name": "01 Scraping Site & Storing Records",
"description": "## This is workflow of scrapping list of travel agents website...",
"purpose": "01 Scraping Site & Storing Records ## This is workflow of scrapping list of travel agents website",
"file_path": "finalworkflows/01-scraping-site-storing-records.json",
"file_name": "01-scraping-site-storing-records"
}
Diese Felder ermöglichen eindeutige Identifikation und Referenzierung jedes Workflows innerhalb des Systems. Die workflow_id dient als primärer Schlüssel für Datenbankoperationen, während workflow_name und description menschenlesbare Informationen für Benutzer bereitstellen.
8.1.2 Strukturelle Analyse-Metriken
Die Metadaten enthalten detaillierte strukturelle Informationen über jeden Workflow:
{
"node_count": 11,
"connection_count": 7,
"complexity_score": "medium",
"node_types": [
"n8n-nodes-base.splitOut",
"n8n-nodes-base.httpRequest",
"n8n-nodes-base.stickyNote",
"n8n-nodes-base.manualTrigger",
"n8n-nodes-base.emailSend",
"n8n-nodes-base.googleSheets",
"@n8n/n8n-nodes-langchain.openAi"
],
"triggers": ["n8n-nodes-base.manualTrigger"],
"integrations": ["emailSend", "googleSheets", "httpRequest", "langchain", "manualTrigger", "openAi"]
}
Diese strukturellen Metriken ermöglichen es dem System, Workflows nach Komplexität zu kategorisieren und ähnliche Strukturmuster zu identifizieren. Der complexity_score wird algorithmisch basierend auf node_count, connection_count und der Vielfalt der verwendeten Node-Typen berechnet.
8.2 Kategorisierung und Klassifikation
8.2.1 Multi-dimensionale Kategorisierung
Jeder Workflow wird in mehreren Dimensionen kategorisiert, um präzise Suche und Matching zu ermöglichen:
{
"categories": ["ai", "communication", "triggers"],
"industries": ["content-creation", "customer-service", "data-processing"],
"use_cases": ["Notification", "Scheduled Reporting", "Webhook Automation"],
"tags": ["ai", "communication", "emailsend", "googlesheets", "httprequest", "langchain", "llm", "manualtrigger", "openai", "splitout", "stickynote", "triggers"]
}
Diese hierarchische Kategorisierung ermöglicht es dem System, Workflows sowohl nach funktionalen Aspekten (categories), Anwendungsdomänen (industries) als auch nach spezifischen Anwendungsfällen (use_cases) zu filtern und zu suchen.
8.2.2 Technische Anforderungen
Die Metadaten dokumentieren alle technischen Abhängigkeiten und Anforderungen:
{
"requirements": {
"credentials": ["Google OAuth2", "Google Service Account", "OpenAI API Key"],
"apis": ["External API Endpoint"],
"services": ["Google", "Openai"]
},
"skill_level": "intermediate",
"estimated_setup_time": "15-30 minutes"
}
Diese Informationen ermöglichen es dem System, bei der Workflow-Generierung automatisch zu prüfen, welche Credentials und Services verfügbar sein müssen, und entsprechende Warnungen oder Konfigurationshinweise zu generieren.
8.3 Datenfluss-Analyse und KI-Integration
8.3.1 Datenfluss-Mapping
Jeder Workflow wird hinsichtlich seines Datenflusses analysiert:
{
"data_flow": {
"sources": ["manualTrigger"],
"destinations": ["emailSend", "googleSheets"],
"transformations": ["splitOut"],
"is_etl": true
},
"has_error_handling": false,
"has_loops": false,
"has_conditionals": false,
"is_scheduled": false
}
Diese Datenfluss-Analyse ermöglicht es dem System, Workflows nach ihren Datenverarbeitungsmustern zu klassifizieren und ähnliche ETL (Extract, Transform, Load) Patterns zu identifizieren.
8.3.2 KI-Funktionalitäten
Besondere Aufmerksamkeit wird KI-integrierten Workflows gewidmet:
{
"uses_ai": true,
"ai_models": ["gpt-4.1-mini-2025-04-14", "gpt-4o"]
}
Diese Informationen sind entscheidend für die automatische Generierung von Workflows, die KI-Komponenten enthalten, da das System entsprechende Node-Konfigurationen und API-Schlüssel berücksichtigen muss.
8.4 KI-generierte Insights und Empfehlungen
8.4.1 Automatische Zusammenfassungen
Jede Metadaten-Datei enthält KI-generierte Zusammenfassungen und Analysen:
{
"ai_summary": "The \"01 Scraping Site & Storing Records\" n8n workflow automates the extraction of travel agent data from websites and organizes it into Google Sheets, while also enabling notifications via email. This enhances operational efficiency for businesses in content creation, customer service, and data processing by streamlining data collection and reporting, ultimately supporting informed decision-making and improved customer engagement.",
"ai_business_value": "Implementing the \"01 Scraping Site & Storing Records\" workflow enhances business efficiency by automating the collection and organization of travel agent data, leading to improved decision-making, timely reporting, and increased productivity, ultimately driving higher ROI through reduced manual labor and faster access to critical insights."
}
Diese KI-generierten Insights helfen Benutzern dabei, den Geschäftswert und die Anwendbarkeit von Workflows schnell zu verstehen, ohne die technischen Details analysieren zu müssen.
8.4.2 Implementierungsempfehlungen
Das System generiert automatisch praktische Implementierungsempfehlungen:
{
"ai_implementation_tips": "1. **Define Clear Triggers**: Set specific criteria for manual triggers to ensure timely and relevant data scraping, enhancing efficiency and reducing unnecessary loads.\n\n2. **Optimize Data Storage**: Use Google Sheets effectively by organizing scraped data into structured formats, making it easier for reporting and analysis.\n\n3. **Test Integrations Thoroughly**: Ensure all integrations (e.g., OpenAI, emailSend) are functioning correctly before full deployment to avoid disruptions in data flow and communication."
}
Diese Empfehlungen basieren auf Best Practices, die aus der Analyse tausender ähnlicher Workflows extrahiert wurden.
8.5 Ähnlichkeits-Mapping und Anwendungsfall-Erweiterung
8.5.1 Verwandte Anwendungsfälle
Jede Metadaten-Datei enthält KI-generierte Vorschläge für ähnliche Anwendungsfälle:
{
"ai_similar_use_cases": "1. **E-commerce Price Monitoring**: Scrape competitor websites for product pricing and store data for analysis, enabling dynamic pricing strategies and alerts for price changes.\n\n2. **Job Listing Aggregation**: Collect job postings from various platforms and store them in a database, facilitating automated notifications for job seekers based on their preferences.\n\n3. **Market Research Data Collection**: Scrape industry reports and trends from multiple sources, storing insights in a centralized location for easy access and analysis by marketing teams."
}
Diese Informationen erweitern die Anwendbarkeit einzelner Workflows und helfen dem System dabei, kreative Lösungen für ähnliche Problemstellungen zu generieren.
8.6 Metadaten-basierte Workflow-Generierung
8.6.1 Pattern-Extraktion aus Metadaten
Das ExampleLearner-System nutzt die strukturierten Metadaten für erweiterte Pattern-Extraktion:
def extract_patterns_from_metadata(self, metadata: Dict) -> WorkflowPattern:
pattern = WorkflowPattern(
complexity=metadata["complexity_score"],
node_types=metadata["node_types"],
integrations=metadata["integrations"],
data_flow_type=metadata["data_flow"]["is_etl"],
ai_enabled=metadata["uses_ai"],
industry_context=metadata["industries"],
use_case_category=metadata["use_cases"]
)
return pattern
Diese Pattern werden in der ChromaDB als zusätzliche Metadaten zu den Embeddings gespeichert und ermöglichen präzisere Ähnlichkeitssuchen.
8.6.2 Kontextuelle Workflow-Empfehlungen
Die Metadaten ermöglichen kontextuelle Empfehlungen basierend auf Benutzeranfragen:
def recommend_workflows(self, user_query: str, context: Dict) -> List[WorkflowRecommendation]:
# Extrahiere Kontext aus Benutzeranfrage
extracted_context = self.extract_context(user_query)
# Filtere Workflows nach Metadaten-Kriterien
filtered_workflows = self.filter_by_metadata(
industry=extracted_context.get("industry"),
complexity=extracted_context.get("complexity"),
ai_required=extracted_context.get("uses_ai")
)
# Ranking basierend auf Ähnlichkeit und Metadaten-Match
recommendations = self.rank_workflows(filtered_workflows, user_query)
return recommendations
8.7 Qualitätssicherung und Kuratierung
8.7.1 Automatische Validierung
Alle 2.500 Workflows durchliefen einen automatischen Validierungsprozess:
def validate_workflow_metadata(self, workflow: Dict, metadata: Dict) -> ValidationResult:
validation_results = []
# Strukturelle Validierung
if len(workflow["nodes"]) != metadata["node_count"]:
validation_results.append(ValidationError("Node count mismatch"))
# Node-Typ-Validierung
actual_node_types = [node["type"] for node in workflow["nodes"]]
if set(actual_node_types) != set(metadata["node_types"]):
validation_results.append(ValidationError("Node types mismatch"))
# Integrations-Validierung
expected_integrations = self.extract_integrations(workflow)
if set(expected_integrations) != set(metadata["integrations"]):
validation_results.append(ValidationError("Integrations mismatch"))
return ValidationResult(validation_results)
8.7.2 Kontinuierliche Aktualisierung
Das Metadaten-System wird kontinuierlich aktualisiert und erweitert:
- Neue Workflows werden automatisch analysiert und kategorisiert
- KI-generierte Insights werden regelmäßig überarbeitet und verbessert
- Benutzer-Feedback wird in die Metadaten-Qualität einbezogen
- Performance-Metriken werden zur Optimierung der Kategorisierung genutzt
Diese umfassende Metadaten-Struktur macht ExampleLearner zu einem der fortschrittlichsten Systeme für automatisierte Workflow-Generierung, da es nicht nur syntaktische Ähnlichkeiten, sondern auch semantische und kontextuelle Übereinstimmungen berücksichtigen kann.