
#38 Expert: Wie kann man 2000 Euro sparen durch lokale Audios/Videos Dvds Transcription? Second Brain Teil 2
Worum geht es in diesem Artikel?
Online Transcriptions Services kosten viel Geld, in meinem Fall beim Aufbau eines Second Brains fallen über 2000 Euro an. Ich zeige wie man den Workflow in 15 min lokal lösen kann
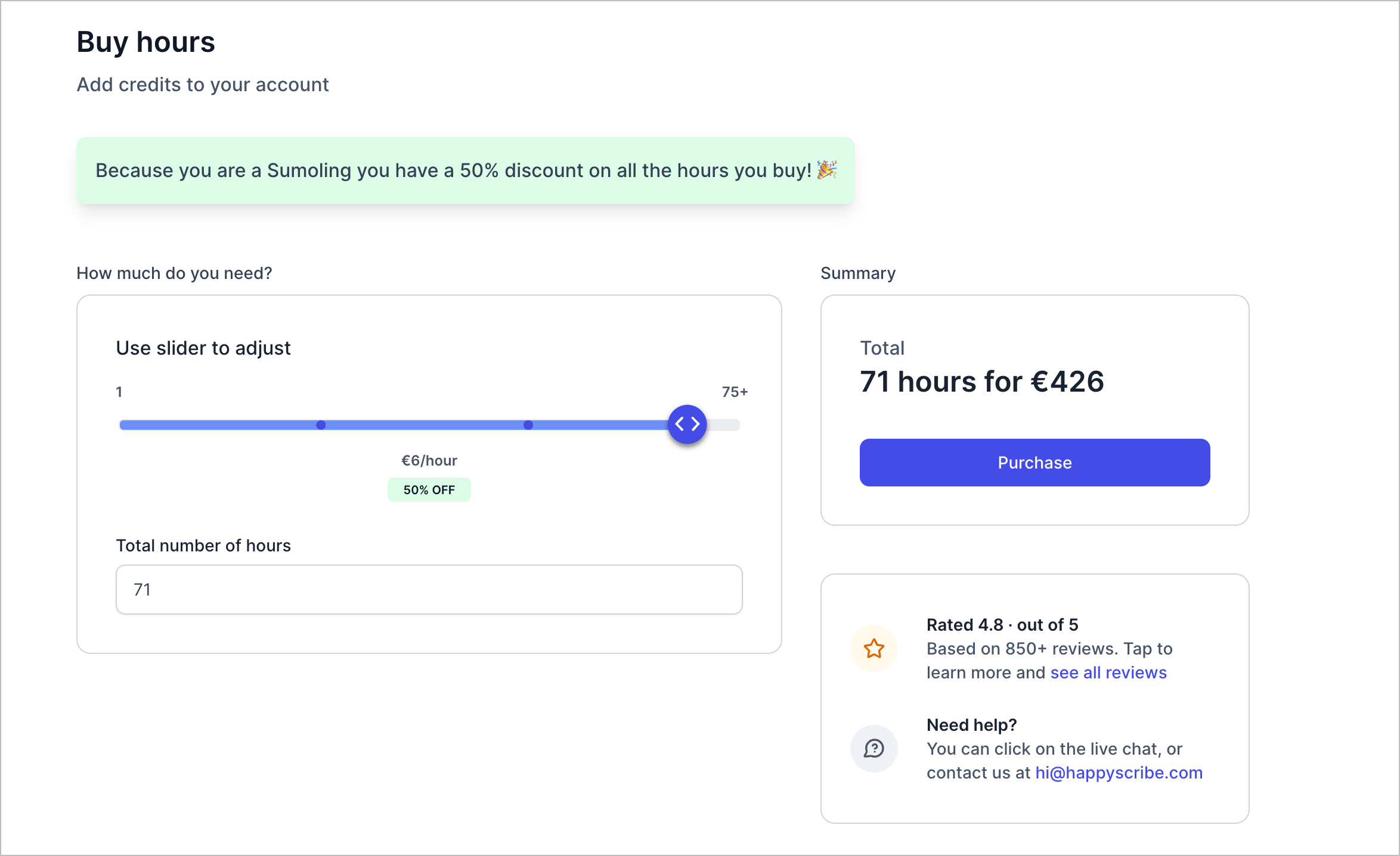
Transcription von Audio/Video/Dvds kostet eine Menge Geld, die meisten Online Transcriptions Services kosten so ca 20 Euro für 6-12 Stunden Audio im Monat im Abo. Einzelpreise liegen ungefähr bei 6 Euro die Stunde.
Bei HappyScribe kosten knapp 80 Stunden 450 Euro. Meine Wissenschafts DVD Sammlung hat mindestens 500 Stunden, das würden über 2000 Euro mit Volumenrabatt bedeuten. Grund genug nach lokalen Services zu schauen.
Hintergrund meine Transkription ist es aus meinen Wissenschafts DVD Chatbots zu machen. Wie herrlich wäre es, wenn ich mit diesen Werken sprechen könnte:

In den Blogbeitrag habe ich beschrieben wie der Workflow Online funktioniert, mit der Einschränkung der Kosten.
Das Ziel ist eine vollkommene lokale KI-Umgebung zu bauen, die es mir ermöglicht meine 500 Stunden automatisch zu transcripieren. Im Test haben 45 min Audio knapp 5 min Übersetzungszeit auf einem Apple Mac Studio Ultra gedauert. Bei 500 Stunden wären das überschlagen knapp 30 Stunden, der Mac ist leistungsfähig genug, so das das parallel zur normalen Arbeit geschehen kann.
Was brauche ich dafür:
- Python Vosk Bibliothek (Python Bibliothek für lokale Übersetzung)
- Vosk Modell (Download)
- Ein Python Programm

Ich habe direkt das grosse deutsche Modell (vosk-model-de-tuda-0.6900k) ausprobiert, vielen Dank an die Informatik der Uni Hamburg für die Erstellung des Modells. Nach dem Download muss man das Modell entpacken und dem folgenden Python Programm den Pfad mitteilen.

Das Python Programm hat mir ChatGPT in einer Minute geschrieben.
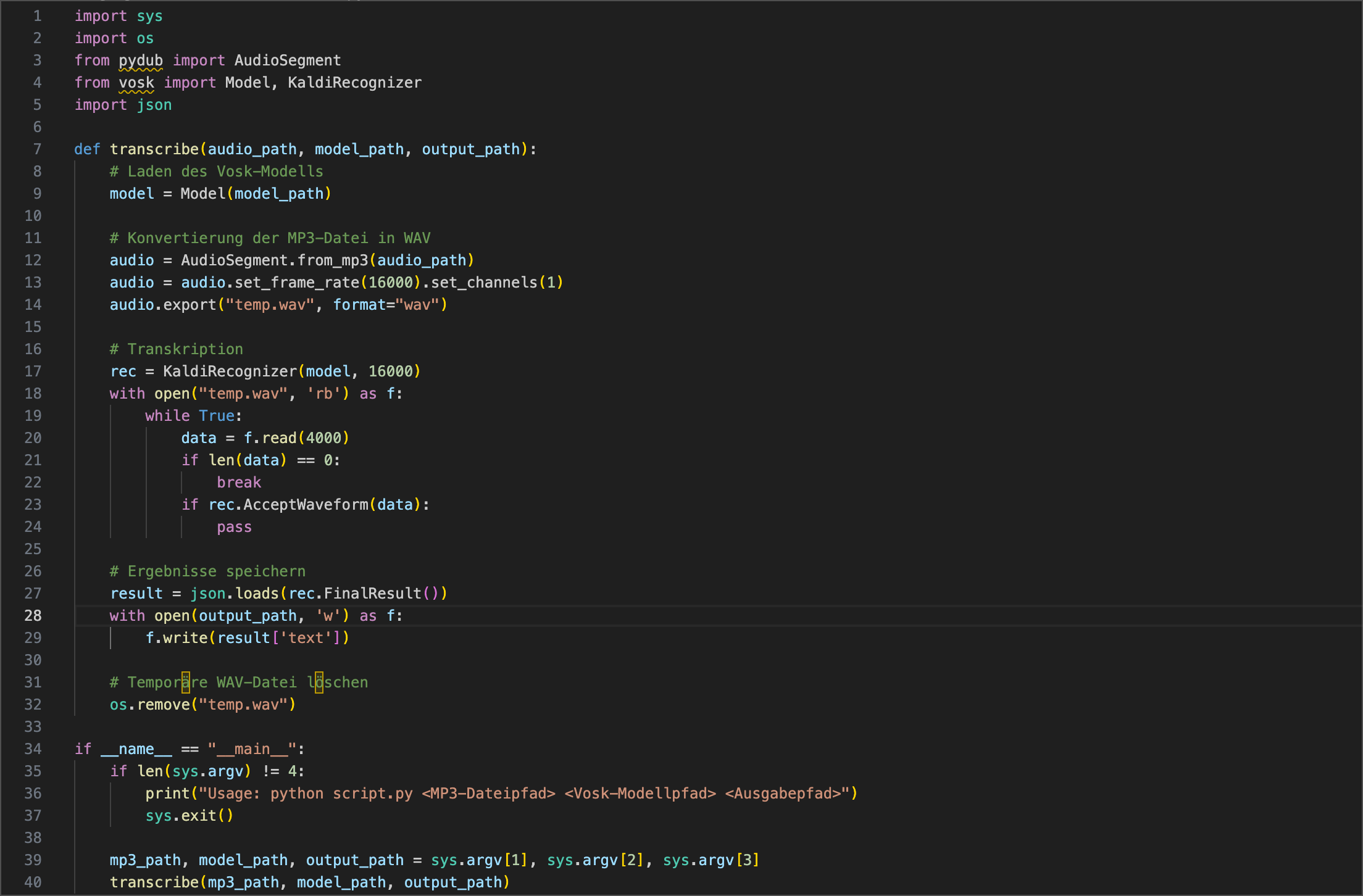
Das Ergebnis in der shell:

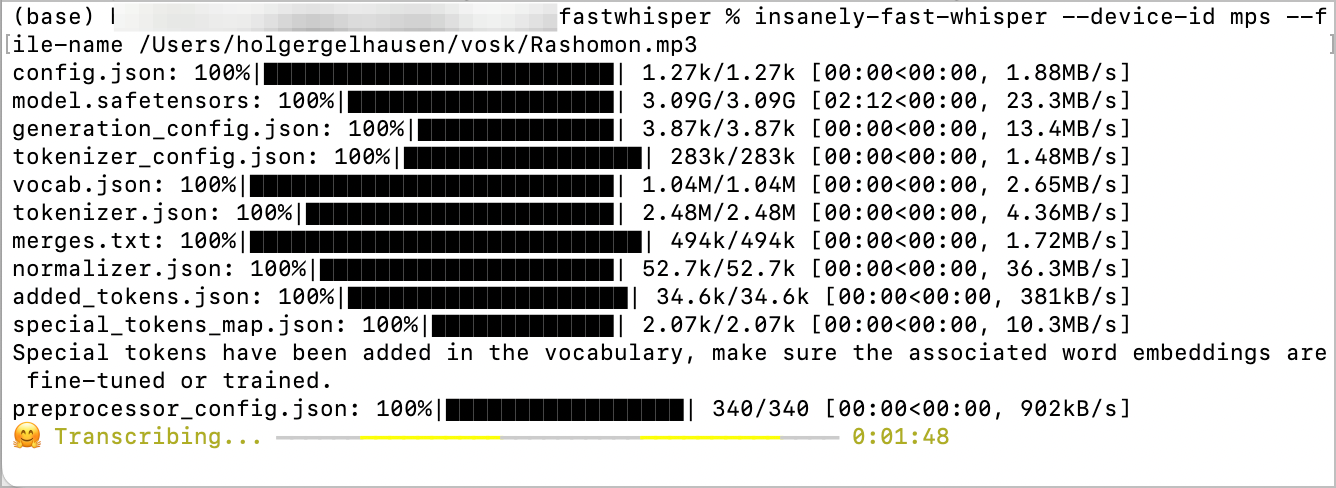
Eine weitere Möglichkeit ist eine neue python Bibliothek
Diese Bibliothek verspricht eine noch schnellere Transcription von Dateien. Im Test hat die Übersetzung von der 41 min großen Datei 05:41 Minuten. Ich probiere noch die größeren und schnelleren Modelle aus.
Jetzt kann ich einen Workflow bauen, der mir alle DVDs transcriptiert, die Texte dann in PrivateGPT hochlädt und daraus Chatbots erstellt.





