
#33 Expert: Wie man sein KI Second Brain baut?
Worum geht es in diesem Artikel?
In dem Workflow zeige ich die Grundlage für ein Second Brain, die systematische und automatische Verarbeitung von Informationen aus PDFs/DVDs und Audio Files
Wie bekomme ich über 1000 PDFs und mehr 200 DVDs/Audio Files mit wertvollen Wissen in mein Second Brain.
Hier in dem Workflow habe ich gezeigt wie man Chatbots zu jeder PDF baut. Die Bots antworten auch entsprechend auf Fragen. Der Nachteil ist, das man für eine strukturierte Beantwortung viele Prompts braucht und es sehr lange dauert. Es fehlt auch die Verarbeitung von DVDs und Audio Files.
Summary des Blogposts
Der Blogpost „Wie man sein KI Second Brain baut“ bietet eine umfassende Anleitung zur effizienten Analyse und Verarbeitung von Büchern und Medieninhalten. Der Autor beschreibt einen Workflow, der den Aufwand für die Transkription und Analyse von Medieninhalten, wie DVDs und Audiofiles, drastisch reduziert (von vier Stunden auf ein paar Minuten). Hierbei wird die Integration von KI-Technologien, insbesondere OpenAI-Assistenten, hervorgehoben. Der Workflow umfasst die Erstellung von Transkriptionen, die automatische Generierung von KI-Assistenten und die systematische Analyse der Inhalte. Ziel ist es, den Lernaufwand zu minimieren und das Wissen effektiver zu nutzen. Der Text behandelt auch Herausforderungen und Optimierungsmöglichkeiten dieses Ansatzes.
Wofür den Aufwand? Business Case
Ich habe ca. 200 DVDs und Audiofiles die ich meistens schon gehört habe (über zwei Jahrzehnte), bei einigen habe ich viele handschriftliche Aufzeichnungen gemacht und Dokumente erstellt, das war alles sehr mühsam. Wenn ich die mit der Hand ins digitale KI-Zeitalter bringen möchte, dann habe ich einen hohen manuellen Aufwand:
Aufwand mit der Hand:
1. Transcription erstellen und hochladen
2. Downloaden
3. Assistenten bauen
4. Viele Chatgpt Eingaben (hier im Workflow knapp 100)
Ich denke der Aufwand für einen DVD/Audio File liegt bei ca. 3-5 Stunden, bei 200 DVDs ca. 800 Stunden.
Viel zu viel Aufwand und das Ergebnis ist nicht einfach reproduzierbar. Deshalb braucht es einen Workflow. An dem Workflow habe ich ca. 16 Stunden gearbeitet (Quick und Dirty) der Aufwand für jede einzelne DVD/Audio reduziert sich auf 1 min.
Das schöne ist, ich lege z.B. 10 DVD in einen Dropbox Folder und der Rest läuft automatisch.
Ein weiterer Punkt, den ich vermisst habe, ich kann jetzt auch viel viel tiefer in einzelne Quellen einsteigen, z.B. Dietrich Dörner in die Logik des Gelingens
Wie lernen fur mich früher war?
Früher, wenn ich für die Uni oder den Beruf lernen wollte oder musste hatte ich folgendes Schema:
Ich machte mir Notizen zu:
- Warum will ich das Buch lesen?
- Wofür kann ich den Inhalt gebrauchen?
- Was weiß ich schon über das Thema: ABC Liste von Vera Birkenbihl
- Betrachtung des Umschlages
- Lesen der Einleitung und oder Zusammenfassung
- Anschauen des Stichwortverzeichnisses
- Schnelles Durchblättern und aufmerksames Anschauen von Kapitelüberschriften und Bilder. Wenn vorhanden Kapitelzusammenfassungen
- Kapitelweises durcharbeiten mit 3-5 Fragen die am Anfang des Kapitels ich mir gestellt habe.
- 10 schwierige Fragen pro Kapitel heraussuchen
- Lern-Larry, den Inhalt des Kapitel in Worte fassen oder Steggreif Rede
- Mindmaps oder Mnemotechnik je nach Wichtigkeit des Stoffes
- Lernkartei nach dem Prinzip des Sebastian Leitners
Folgende Mindmaps mit Mnemotechnik sind über 30 Jahre alt und waren eine Vorbereitung auf eine Klausur.

Content Factory: Wie liest man seine Lieblings Bücher / Videos automatisch
Viele Bücher habe ich als PDF oder als DVD/Audio. Die Bearbeitung ist etwas umständlicher, der einzige Weg vor der KI-Zeit waren Bildschirmfotos zu machen (selbstverständlich gab es auch andere Wege, die waren aber sehr teuer oder man musste programmieren)

Ich möchte die Inhalte der DVD/Audios automatisch transkribieren und als Ziel einen KI Workflow entwickeln der das Wissen aus den Quellen mir als Co-Worker zur Verfügung stellt.
Der Klassiker um Bücher / PDF zu lesen ist Mortimer J. Adler „How to read a Book“.

Welche Fragen sollte man an ein Buch stellen?
Mortimer stellte diese Fragen:
Was ist das Thema des Buches?
-
- Versuchen Sie, das Hauptthema oder die zentrale Idee des Buches in einem einfachen Satz oder einer Frage zusammenzufassen.
- Was sind die Hauptargumente oder Ideen?
- Identifizieren Sie die wesentlichen Argumente oder Punkte, die der Autor vorbringt, um sein Thema zu unterstützen.
- Welche Beweise oder Beispiele verwendet der Autor?
- Achten Sie auf die Beweise, Beispiele oder Anekdoten, die der Autor verwendet, um seine Argumente zu stützen.
- Was sind die wichtigsten Schlussfolgerungen?
- Überlegen Sie, zu welchen Schlussfolgerungen der Autor kommt und wie diese das Gesamtthema des Buches beeinflussen.
- Was sind die zugrundeliegenden Annahmen?
- Identifizieren Sie Annahmen, die der Autor möglicherweise macht, und bewerten Sie, wie diese die Argumentation beeinflussen.
- Wie ist das Buch strukturiert?
- Betrachten Sie, wie das Buch aufgebaut ist und wie diese Struktur die Darstellung des Themas und der Argumente unterstützt.
- Welche Fragen bleiben unbeantwortet oder welche Probleme sind ungelöst?
- Überlegen Sie, welche Aspekte des Themas möglicherweise nicht vollständig behandelt wurden oder welche Fragen nach der Lektüre offen bleiben.
- Welchen Einfluss hat dieses Buch auf mein Denken oder meine Sichtweise?
- Reflektieren Sie darüber, wie das Buch Ihr Verständnis des Themas beeinflusst oder verändert hat.
Diese Fragen kann ich wunderbar in einen KI-Workflow übernehmen.
Welche Fragen stelle ich an die Kapitel?
Hier der erste Entwurf der Fragen, die werden noch optimiert.
- Welche wichtigen Konzepte und Fachbegriffe werden in dem Kapitel der PDF eingeführt?
- Wie kann man eine prägnante Zusammenfassung dieses Kapitels der PDF erstellen?
- Welche neuen Begriffe oder Konzepte werden in diesem Kapitel der PDF eingeführt?
- Welche weiterführenden Fragen ergeben sich aus der Analyse der PDF?
- Wie würde man das Gelernte aus der PDF jemandem erklären, der sie nicht gelesen hat?
- Welche Kritikpunkte könnte man gegen die Argumente des Autors in der PDF vorbringen?
- Welche Fragen wirft dieses Kapitel der PDF auf?
- Wie kann man eine Wissensstandüberprüfung durchführen, um zu verstehen, ob die Inhalte des Kapitels verstanden wurden? (Entwicklung von 10 Fragen und Antworten aus dem Kapitel)
- Was sind 10 Do’s und Don’ts, die aus dem Kapitel der PDF abgeleitet werden können?

Herausforderung des Workflows
Früher habe ich mir Snapshots gemacht, jetzt möchte das die Inhalte automatisch transkribiert werden und als PDF gespeichert werden.
Die Anforderungen an den Workflow:
Grobworkflow:
Aus DVD/Audios werden PDF erstellt, aus diesen PDF werden OpenAI Assistants generiert und diese Assistants zur Quelle systematisch gefragt.
Detailworkflow:
- Als DVD/Audio Datei: in ein Cloud Verzeichnis legen und der Rest läuft voll automatisch.
- Upload zu Happyscribe (Transcription Cloudsoftware)
- Transcription
- Wenn die Transcription fertig ist, dann download in eine anderes Verzeichnis
- Erstellung einer PDF
- Kopieren eines PDF in ein anderes Verzeichnis (MakeAssistent)
- Als PDF: Kopieren der Datei in das Verzeichnis (MakeAssistent)
- Upload der PDF zu Airtable
- Automatische Erstellung eines OpenAI Assistants
- Der Assistent hat als Quelle die PDF und erstellt automatisch die Antworten
- Systematische Analyse der PDF nach den Fragen für das PDF und der Kapitel
- Die Fragen und Antworten je Buch und Kapitel werden nach Airtable übertragen
- Es wird ein Google Doc mit allen Fragen und Antworten erstellt
- Jede Frage und Antwort wird an Airtable übertragen
- Automatische Erstellung von Anki-Cards
Kommen wir jetzt zu den Workflows
Happy Scripe Workflow
Der Happy Scribe Workflow besteht aus zwei Teilen:
Automatischer Upload
Hier ist noch ein älteres Bild, das auf einen Trigger in Airtable reagiert, Zapier kann Dropbox Ordner überwachen und wenn ein neuer File vorhanden ist, dann Aktionen auslösen

Wenn die Transcription fertig ist, dann startet ein automatischer Download des Textes.
Die Transkription dauert oft länger, kein Grund zu warten, wenn die Transkription fertig ist, dann wird die Datei automatisch „runtergeladen“

Der Text ist jetzt bereit für einen KI Workflow, vorher brauchen wir noch einen OpenAI Assistenten der die Fragen inhaltlich zur PDF beantwortet
Automatischer Bau eines OpenAI Assistenten
Die Fragen zur PDF soll ein OpenAI Assistent beantworten, die Anforderungen an den Workflow sind Vollautomatisierung, brauchen wir auch die automatische Erstellung eines solchen Assistants.
Hier gibt es eine wunderbare Implementierung von Zapier. Über den Trigger in Airtable wird ein Assistant angelegt und die Nummer des Assistent in Airtable eingetragen.

Eintrag in der Assistants ID in Airtable. Die Assistants ID brauche ich um nachher im Workflow gezielt die PDF erstellen zu lassen.

Inhaltsverzeichnis oder Gliederung erstellen
Die DVDs oder Audiofiles haben meistens keine Gliederung, also soll mir der Assistent eine Gliederung erstellen. Das ist ein wichtiger Prozess, den ich mit einem Korrektiv ausführe, das heisst ein Aufruf der KI überprüft das Ergebnis der vorherigen Ergebnis. Im dritten Schritt werden die Verbesserungen eingearbeitet.
Workflow:
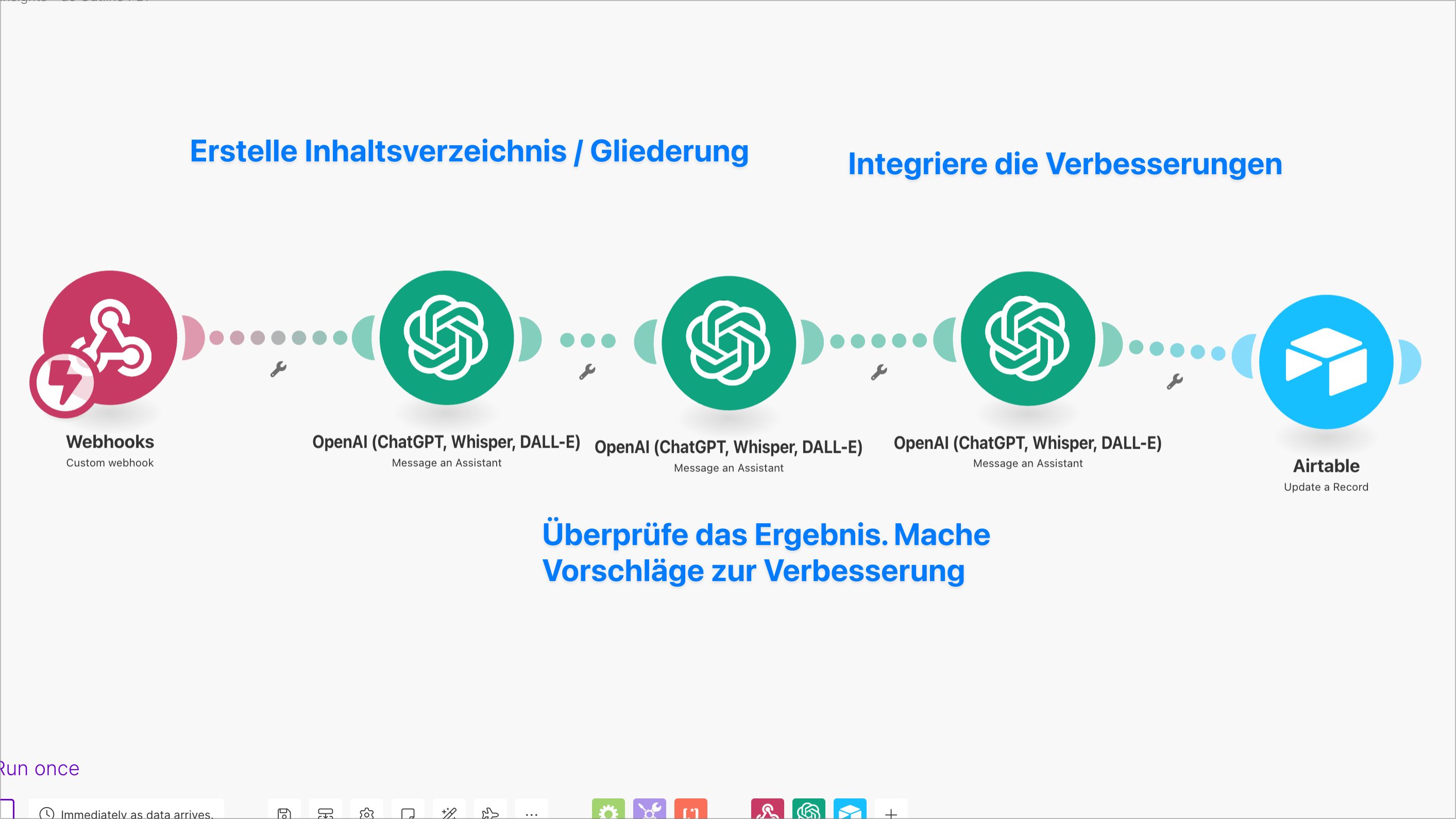
Die nächsten DVDs (Die Logik des Gelingens)

Was nicht funktioniert
Workflow
Ich habe einen grossen Workflow gemacht, der für jedes Kapitel der PDF bis zu 10 Fragen stellt, das wären dann im Schnitt über 100 Abfragen an OpenAI. Das dauert lange. Die Workflows in Make.com dürfen im Schnitt nur 45 min laufen und ich bin immer über die 45 min Laufzeit gekommen.

Der Workflow ist einfach, das Herzstück ist, das die Fragen zu den Kapiteln in dem Google Doc enthalten sind.
Ergebnis:

Alle Fragen und Antworten sind in einem Google Doc zusammengeführt.
Optimierungspunkte:
1. Aufteilung des Workflows zur paralleler Verarbeitung
2. Jede Frage und Antwort soll in eine Airtable Datenbank zurückgeschrieben werden. Dann lassen sich die einzelnen Fragen / Antworten leichter weiterverarbeiten oder in die nächsten KI-Bots bringen
Final Workflow
Der Workflow braucht einen Split und zwei Teile:
Workflow 1: Kapitel splitten
Der Workflow ruft für jedes Kapitel einen Subflow auf, damit können die Tasks parallel laufen
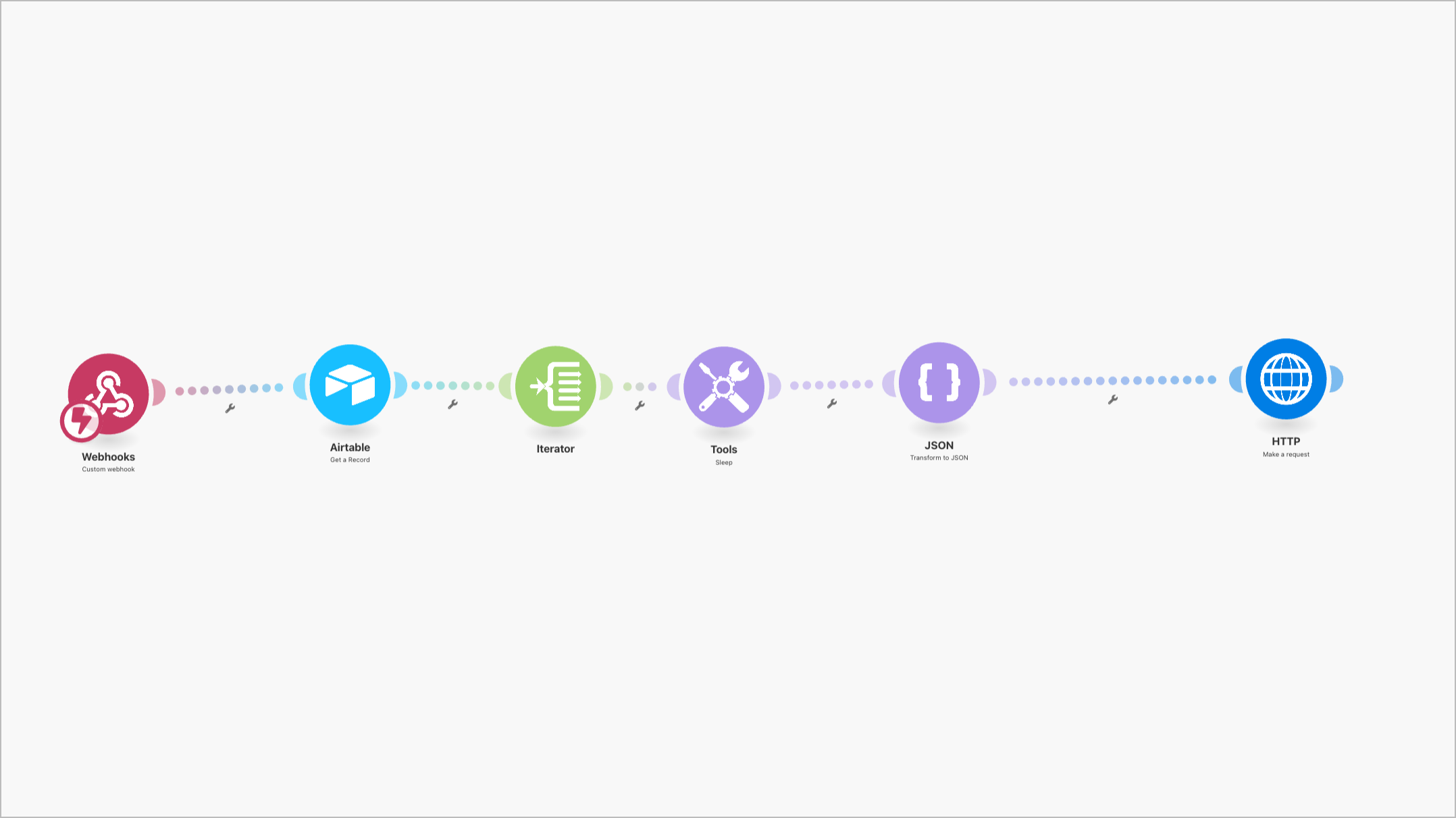
Workflow 2: Kapitelweises abarbeiten der Fragen
Hier das Herzstück, für jedes Kapitel werden die Fragen gestellt und in ein neues Dokument übertragen und in Airtable hochgeladen.

Filter in Airtable
In Airtable kann ich dann nach den Inhalten filtern oder weitere Aktionen anstoßen.
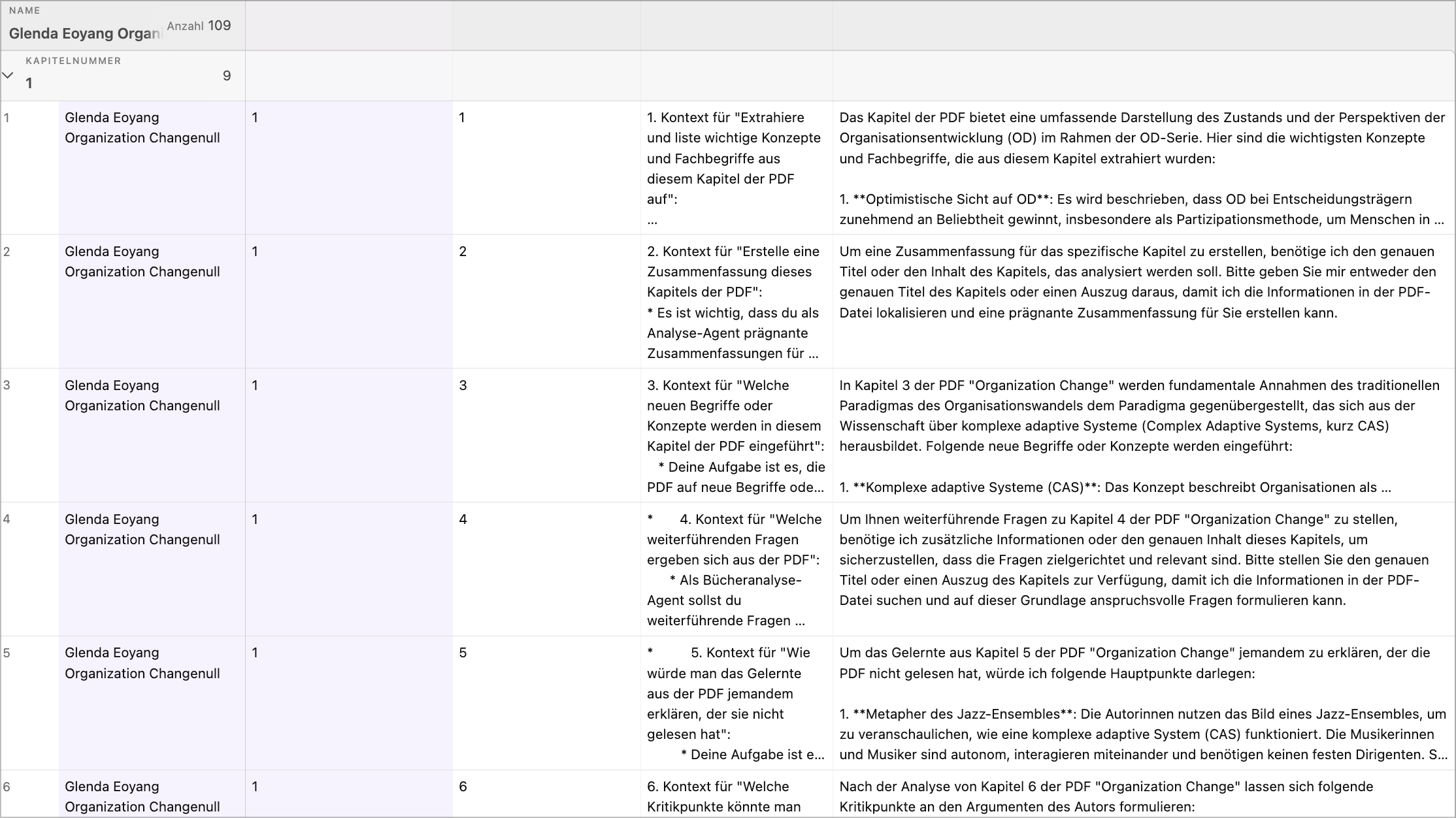
In der Tabelle sieht man, das einzelne Prompts noch nicht so gut funktionieren und angepasst werden müssen.
Second Brain
Aus diesen Inhalten lassen sich dann Workflows zu einem Second Brain ableiten.
- Proaktives Fragen: 10 min am Tag für Recalls zu verschiedenen Themen (Sebastian Leitner Prinzip)
- Die KI geht mit mir in einen Dialog, wie oben in dem Lernkonzept beschrieben
- Die Inhalte können auch automatisch vertaggt werden, so das eine Wissensmap erstellt wird.

Summary und Ausblick
Mit dem Workflow, der systematisch Wissen analysiert, lassen sich jetzt weitere Workflows anbinden:
- Kapitelweise Erstellung von Slides/Übungsaufgaben/Summaries/Ankicards
- Videos zu jedem Kapitel
- Aufbau einer Prompting Engine, das heisst die Quelle wird zu einem KI-Ratgeber gemacht
- Aufbau eines Learning KI-Bots zu dem Thema (Second Brain)
Dieser Artikel war die Grundlage für weitere Workflows zum Second Brain.





